L'intelligence artificielle : l'expertise partout accessible à tous

Introduction
L’omniprésence de l’intelligence artificielle
Qu’est-ce que l’intelligence ?
Une brève histoire de l’intelligence artificielle et de ses acteurs principaux
Les grandes ruptures de 2011
Du big data au data mining
L’importance e l’apprentissage
Les grands acteurs de l’intelligence artificielle
L’impact sur les métiers
La médecine
Le futur
Conclusion





Hiroshi Ishiguro et son dual robotique.

Source :
« Hiroshi Ishiguro : Robots like mine will replace pop stars and Hollywood actors », Internationalbusiness, Times, 22nd of March, 2015.
Graphique 1 : Exemple de données de la base ImageNet
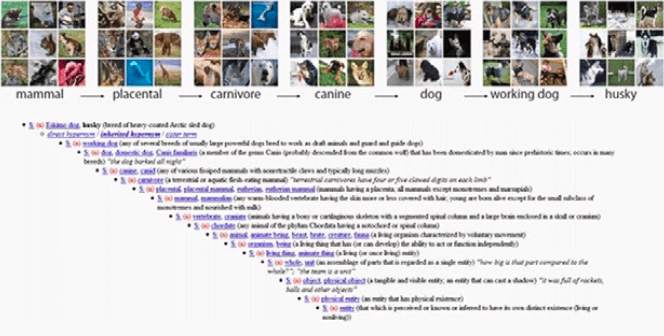
Source :
Image extraite du site web de ImageNet.
La possession de ces données donne un pouvoir énorme aux GAFA17 et à leurs équivalents chinois. Néanmoins, Google nous offre des interfaces de programmation permettant d’interroger les siennes. Google Maps, par exemple, autorise l’accès à la cartographie de la planète entière. Google propose un site où nous pouvons comparer les tendances sur plusieurs mots- clés, avec possibilité de zoomer sur des zones géographiques, sur des échelles de temps, ou bien de filtrer sur des catégories. À titre d’exemple, nous pouvons ainsi comparer l’évolution de l’intérêt pour la recherche « Macron » versus « Trump » entre novembre 2016 et novembre 2017 (voir graphique 2)18.
Graphique 2 : Trump versus Macron dans une requête Google
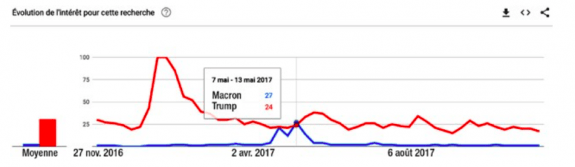
Google trends : https://trends.google.com/trends/explore?q=Macron,Trump.
On voit que les recherches « Macron » ont dépassé les recherches « Trump » début mai 2017. Que s’est-il passé à ce moment? Pour le savoir, il suffit de regarder sur la même page du site, un peu plus bas, quelles sont les requêtes associées (voir graphique 3). En position 3 et 4, nous trouvons la fameuse poignée de main entre Emmanuel Macron et Donald Trump qui a enthousiasmé le monde entier ! Nous savions que cette poignée de main était hautement symbolique. Google l’a quantifiée.
Graphique 3 : Requêtes associées
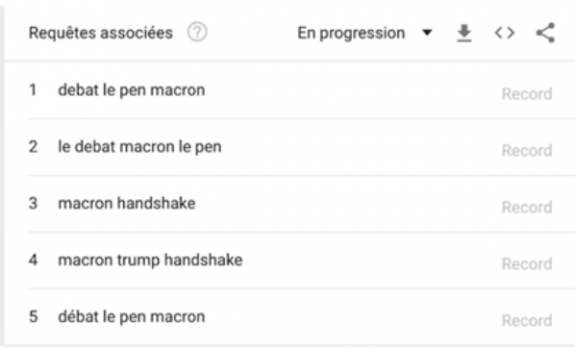
trends.google.com/trends/explore?q=Macron,Trump.
Il est également possible de faire des zooms par région sur la même requête (voir graphique 4). Le président des États-Unis retient l’attention du continent américain, mais en Russie, en France et dans certains pays africains, c’est le président Macron qui l’emporte.
Graphique 4: Requêtes Trump contre Macron selon les pays
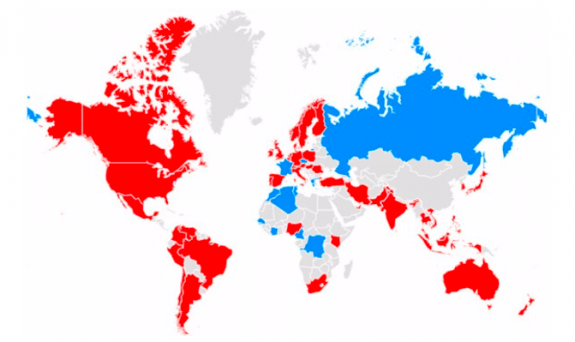
https://trends.google.fr/trends/.

Pour arriver à ces résultats, l’algorithme a dû passer par une phase d’apprentissage, qui n’est jamais vraiment terminée.
Il y a trois grandes époques de l’intelligence artificielle. Le graphique 5 l’illustre bien : la machine commence à jouer aux échecs, l’apprentissage lui permet de faire la distinction entre spam et courriel normal, et l’apprentissage profond lui permet de dire qu’une image contient un chat.
Graphique 5 : Les trois niveaux de l’intelligence artificielle

Michael Copeland, « What’s the Difference Between Artificial Intelligence, Machine Learning, and Deep Learning? », blogs.nvidia.com/blog/2016/07/29/ whats-difference-artificial-intelligence-machine-learning-deep-learning-ai/.
Graphique 6 : Evolution du coût du séquençage génomique
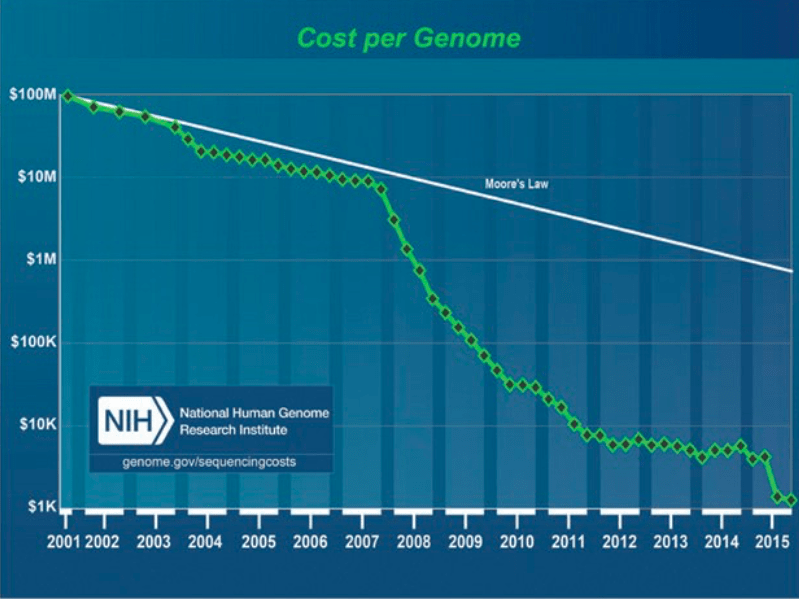
Source :
Aux États-Unis, la société 23andMe propose votre séquençage ADN pour la modique somme de 99 dollars si vous souhaitez juste savoir qui sont vos ancêtres, et de 199 dollars si vous voulez savoir quelles sont les maladies génétiques dont vous êtes porteur36. Ce séquençage génétique devient surtout utile lorsqu’il est croisé avec des bases de données. C’est donc, une fois de plus, dans la constitution de ces bases et leur interprétation par des moteurs d’intelligence artificielle que se situe la valeur. La plus grande base est Genbank, qui contient près de 200 millions de séquences ADN en accès libre (voir graphique 7).
Graphique 7 : Evolution du nombre de données de séquences d’ADN
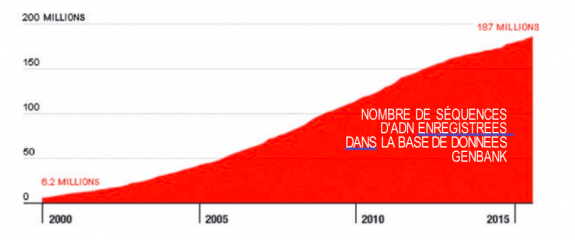
National Center for Biotechnology Information.
Graphique 8 : croissance exponentielle de la puissance de calcul
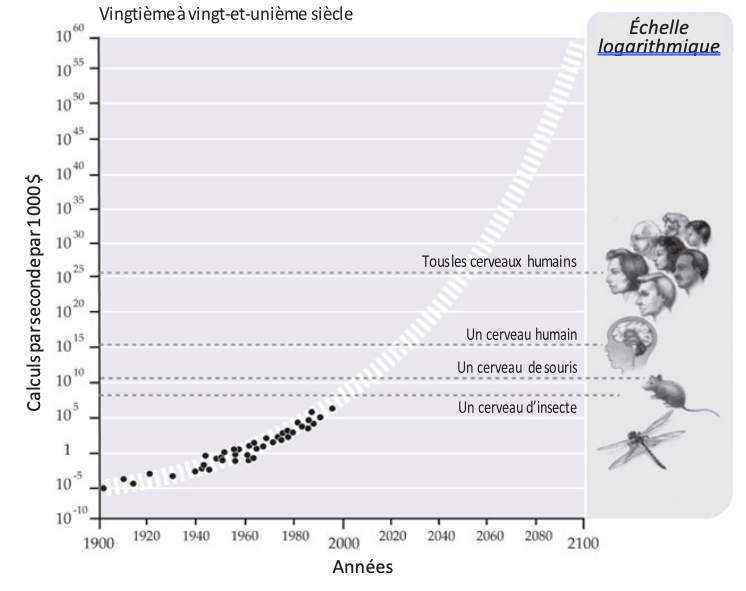
Source :
« Comment le futur de l’intelligence artificielle pourrait révolutionner le monde d’ici 25 ans », Huffingtonpost, Gregory Rozières, 5 octobre 2016.











Aucun commentaire.