Structure économique et sociale des territoires et vote populiste en France

Introduction
La situation économique et sociale des territoires
Croissance et développement dans les territoires
L’hétérogénéité sociale
Évolution selon l’indice de « privilège » communal
Qui vote pour qui dans les territoires ?
État des lieux à partir des données individuelles
Résultat des données communales
Quelques comparaisons avec les élections de 1981
Expliquer les votes
Corrélation et pouvoir explicatif des variables clés
Quel bon modèle explicatif ?
Conclusion

Élections départementales et régionales 2021 : une analyse cartographique

Le Front national face à l’obstacle du second tour

Le Front national en campagnes. Les agriculteurs et le vote FN.

Régionales 2015 (1) : vote FN et attentats

Régionales 2015 (2) : les partis, contestés mais pas concurrencés

Départementales de mars 2015 (1) : le contexte

Départementales de mars 2015 (2) : le premier tour

Départementales de mars 2015 (3) : le second tour

Les Européens abandonnés au populisme

L’AfD : l'extrême droite allemande dans l'impasse

Victoire populiste aux Pays-Bas : spécificité nationale ou paradigme européen ?

Le FPÖ au défi de l'Europe : radicalité idéologique et contrainte électorale en Autriche

Fratelli d’Italia : héritage néofasciste, populisme et conservatisme

L'émergence d'une gauche conservatrice en Allemagne : l'Alliance Sahra Wagenknecht pour la raison et la justice (BSW)

Italie 2022 : populismes et droitisation
Carte des aires d’attraction en France en 2020
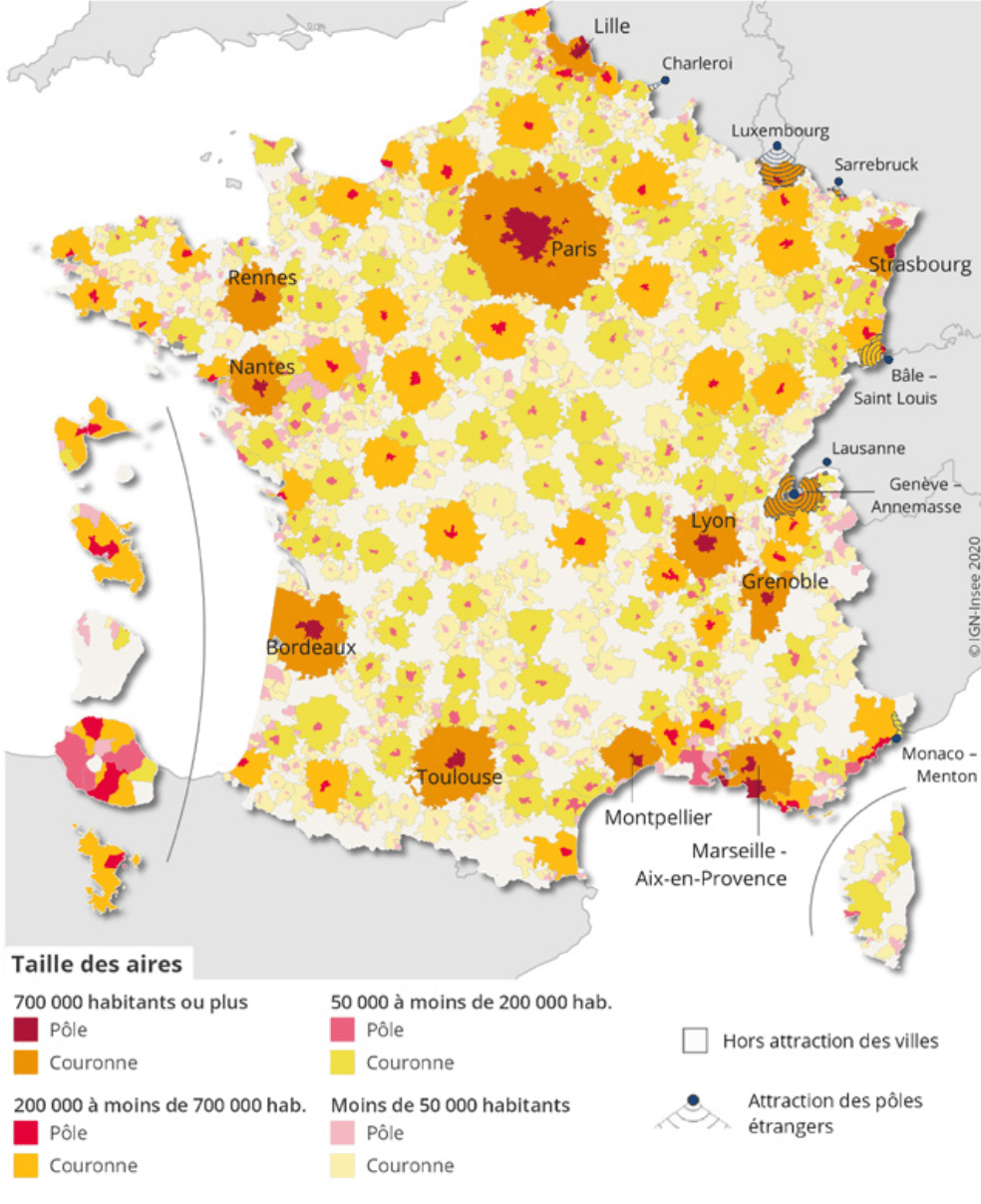
Source :
Insee
Tableau 1 : poids des aires d’attraction selon la population et le revenu
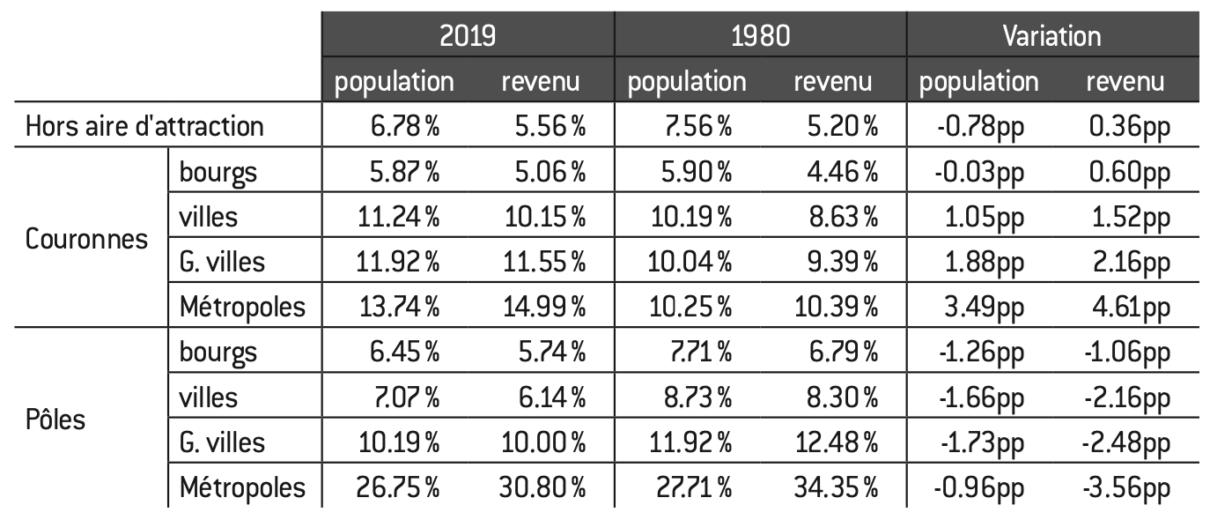
Source :
Calculs de l’auteur à partir des données de l’Insee pour la France métropolitaine.
Note : Statistiques obtenues à partir de l’agrégation des données communales.
Lecture : En 2019, les pôles des aires d’attraction de plus de 700.000 habitants (métropoles) représentent 26,8% de la population et 30,8% du revenu total. En 1980, ces valeurs étaient respectivement de 27,7% et 34,4%.
Interprétation : Le poids des grands centres urbains, que ce soit en termes de population ou de revenu, tend à diminuer depuis 1980 au profit des zones périphériques, en particulier les banlieues des aires d’attraction supérieures à 200.000 habitants.
Figure 1 : Convergence du revenu par adulte entre commune
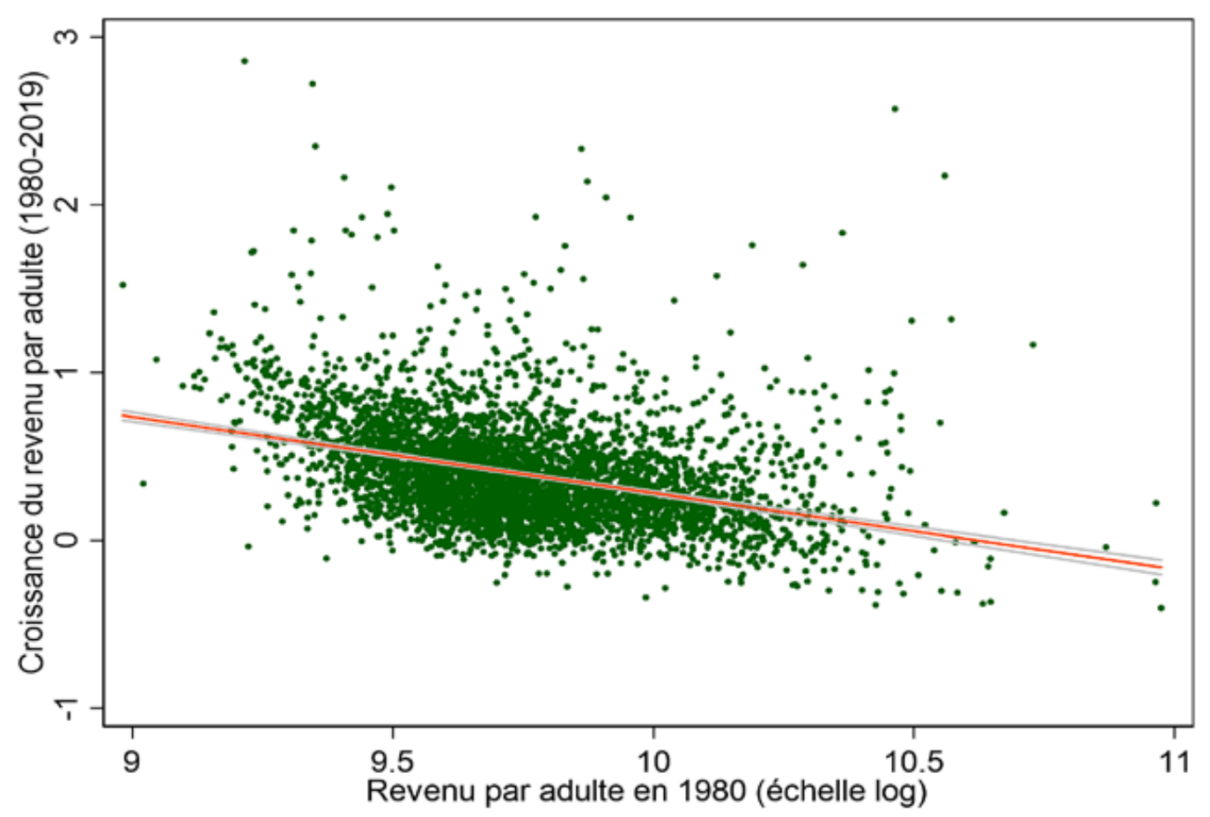
Source :
Calculs de l’auteur à partir des données de l’Insee et de Piketty et Cagé13.
Note : Revenu moyen par adulte, communes de plus de 1000 habitants. L’équation sous-jacente est la suivante : Croissance1980→2019= 4.88 – 0.46 × ln (revenu par adulte)1980 ; R2 = 0.14.
Lecture : Lorsque le niveau de développement communal en 1980 augmente de 10%, le taux de croissance du revenu par adulte entre 1980 et 2019 est en moyenne plus faible de 4,6pp.
Interprétation : Les inégalités de revenu entre communes diminuent depuis 1980, plus une commune est pauvre plus le taux de croissance du revenu moyen y est élevé relativement aux autres communes.
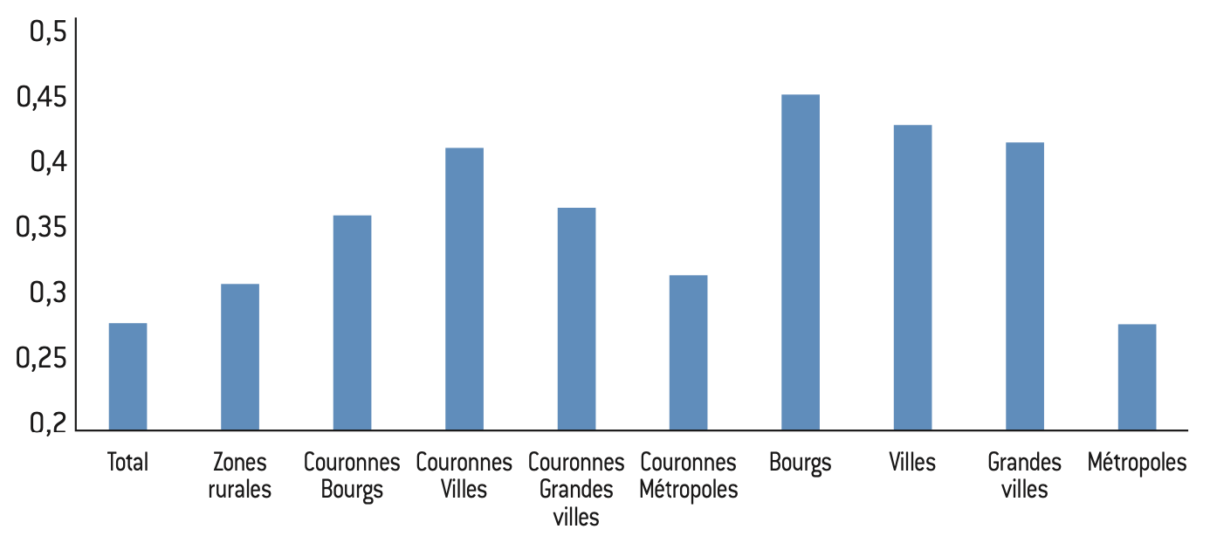
Figure 2 : Taux de croissance du revenu moyen par adulte des communes selon l’aire d’attraction
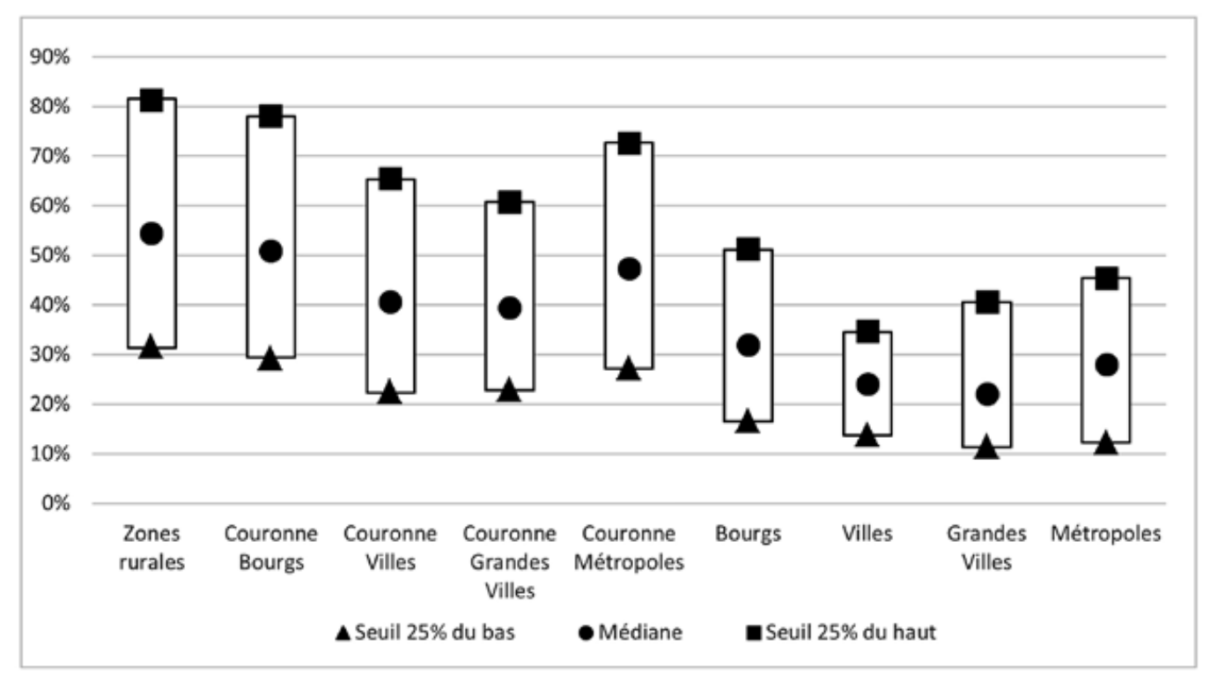
Source :
Calculs de l’auteur à partir des données de l’Insee et de Piketty et Cagé14.
Note : Croissance du revenu moyen par adulte, communes de plus de 1.000 habitants. Les zones rurales correspondent aux communes hors aire d’attraction. Les bourgs sont les aires des moins de 50.000 habitants, les villes sont les aires (pôle et couronne) de 50.000 à 200.000 habitants, les grandes villes les aires de 200.000 à 700.000 habitants, les métropoles les aires de plus de 700.000 habitants
Lecture : Les communes des pôles des aires d’attraction de moins 50.000 habitants (bourgs) affichent un taux de croissance médian du revenu par habitant de 32% entre 1980 et 2019. En outre 25% des communes des bourgs ont eu un taux de croissance supérieur à 51% et 25% d’entre elles ont eu un taux de croissance inférieur à 16%.
Interprétation : Depuis 1980, la croissance dans les centres est plus faible qu’en périphérie et ceci n’est pas le fait d’une forte hétérogénéité des taux de croissance à l’intérieur de chaque type de territoire. Autrement dit, même si toutes les régions ne sont pas logées à la même enseigne, la périphérie n’est pas, en moyenne, perdante des transformations du système économique et social des quarante dernières années, notamment de la mondialisation.
Figure 3 : Taux de croissance de la population selon l’aire d’attraction depuis 1980
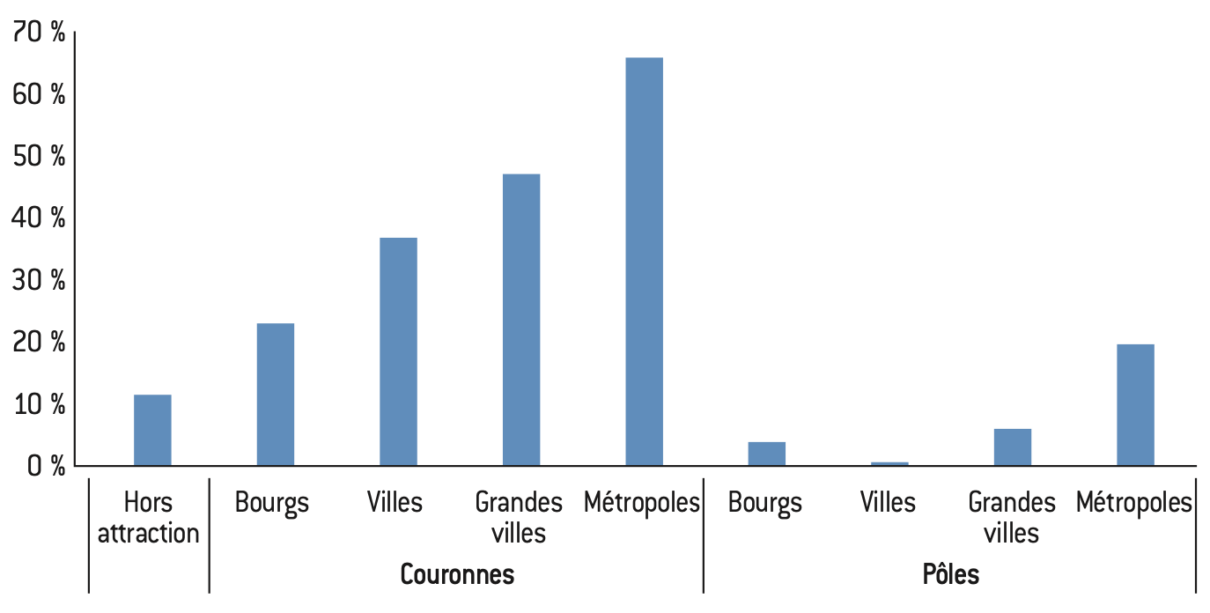
Source :
Calculs de l’auteur à partir des données de l’Insee.
Note : Les bourgs sont les aires (pôle + couronne) de moins de 50.000 habitants, les villes sont les aires de 50.000 à 200.000 habitants, les grandes villes les aires de 200.000 à 700.000 habitants, les métropoles les aires de plus de 700.000 habitants.
Lecture : Le taux de croissance moyen de la population des couronnes des aires d’attraction de plus de 700.000 habitants (métropoles) est de 66,5% depuis 1980.
Interprétation : La population s’est déplacée dans les couronnes des aires d’attraction, délaissant les grands centres urbains. En outre, la population des zones plus reculées s’accroît positivement depuis 1980, il n’y a donc pas de stricte désertification des zones rurales.
Figure 4 : Revenu par adulte en 2019 selon les territoires
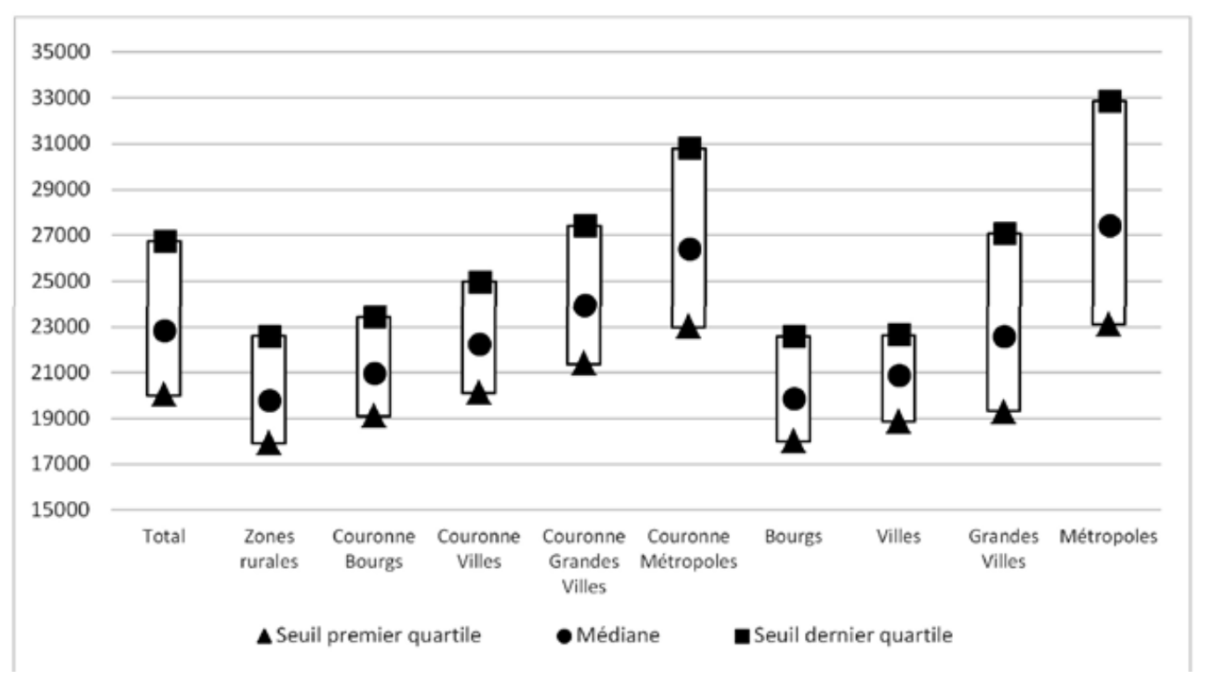
Source :
Calculs de l’auteur à partir des données de l’Insee et de Piketty et Cagé15.
Note : Revenu moyen par adulte, communes de plus de 1.000 habitants. Les zones rurales correspondent aux communes hors aire d’attraction. Les bourgs sont les aires des moins de 50.000 habitants, les villes sont les aires (pôle et couronne) de 50.000 à 200.000 habitants, les grandes villes les aires de 200.000 à 700.000 habitants, les métropoles les aires de plus de 700.000 habitants.
Lecture : La commune médiane des pôles des aires d’attraction de moins 50.000 habitants (bourgs) affiche un revenu moyen par adulte de 19 840€ en 2019. En outre 25% des communes des pôles bourgs ont un revenu moyen par adulte inférieur à 19 992€ alors que 25% d’entre elles ont un revenu moyen par adulte supérieur à 22 577€.
Interprétation : Même si les écarts diminuent entre les territoires depuis quarante ans, les populations des communes sont aujourd’hui d’autant plus aisées qu’elles appartiennent à une grande aire d’attraction, que ce soit au sein des pôles ou des couronnes.
Figure 5 : Part des ouvriers et employés selon le territoire
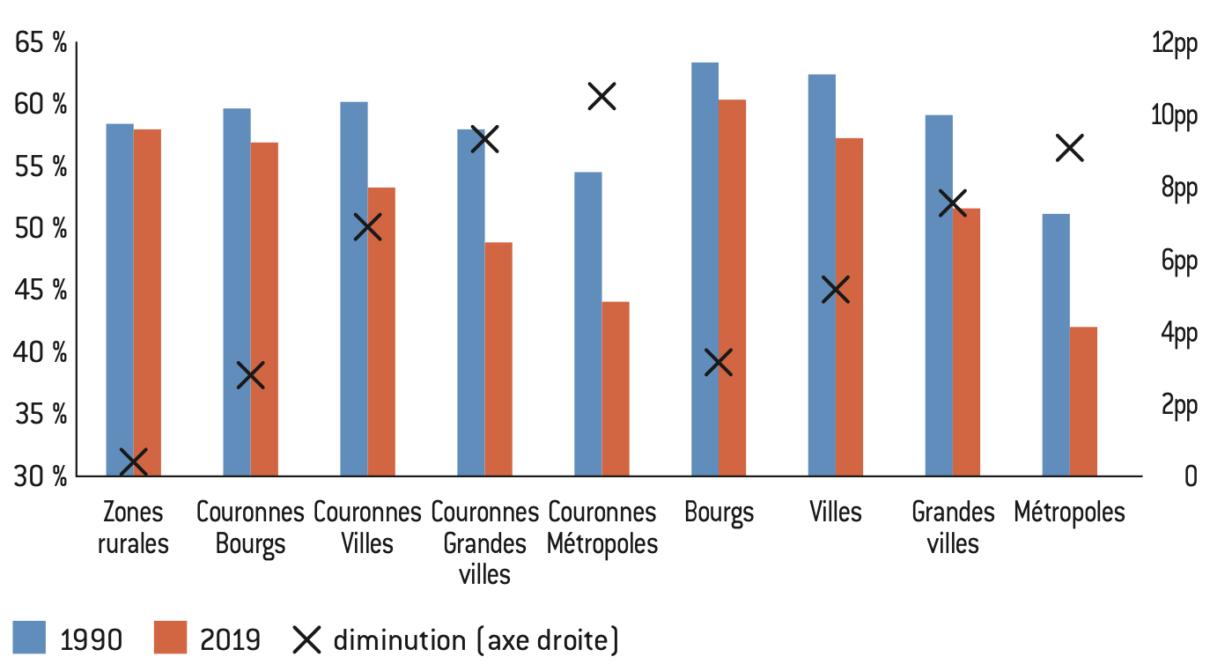
Source :
Calculs de l’auteur à partir des données de l’Insee et de Piketty et Cagé16.
Note : Ce graphique mesure la part des ouvriers et employés dans la population active totale des communes de plus de 1.000 habitants selon le type de territoire en 1990 et en 2019. L’échelle de droite mesure la baisse de cette part sur cette période.
Lecture : La part moyenne des ouvriers et employés dans les communes appartenant aux couronnes des « villes » est passée de 59,9% en 1990 à 53,1% en 2019, soit une diminution de 6,8pp.
Interprétation : La part des métiers les moins qualifiés a diminué dans tous les territoires depuis 1990, cependant, la baisse est d’autant plus forte que l’aire d’attraction est grande. Le contraste socioprofessionnel selon les types de territoires est de plus en plus important.
Figure 6 : Part des diplômés du supérieur selon le territoire
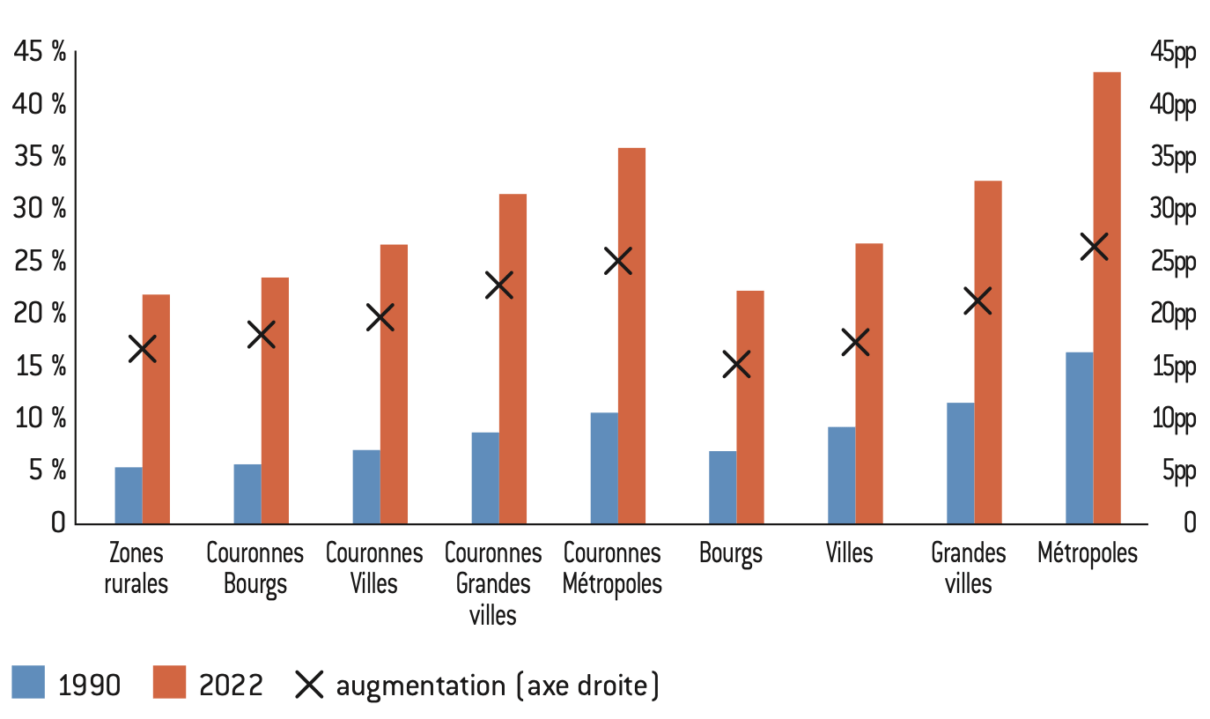
Source :
Calculs de l’auteur à partir des données de l’Insee et de Piketty et Cagé17.
Note : Ce graphique mesure la part des diplômés du supérieur dans la population totale des communes de plus de 1.000 habitants selon le type de territoire en 1990 et en 2022. La croix noire indique l’augmentation de cette part sur cette période.
Lecture : La part moyenne des diplômés du supérieur dans les communes appartenant au pôle des « villes » est passée de 9,3% en 1990 à 26,7% en 2022 soit une hausse de 17,4pp.
Interprétation : La part des diplômés du supérieur a augmenté dans tous les territoires depuis 1990, cependant, la hausse est d’autant plus forte que l’aire d’attraction est grande. Le contraste entre les types de territoires selon le niveau de diplôme apparaît de plus en plus important.
Figure 7 : Convergence sociale entre communes
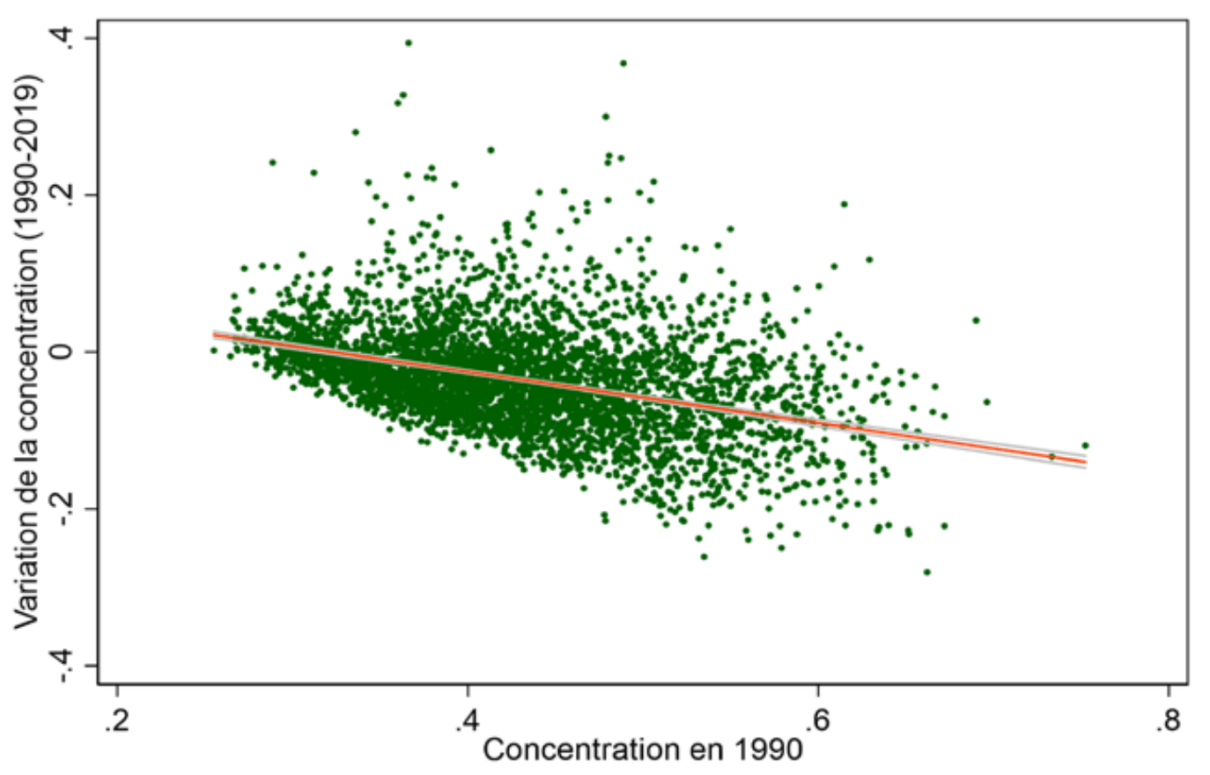
Source :
Calculs de l’auteur à partir des données de l’Insee et de Piketty et Cagé18.
Note : La concentration socioprofessionnelle est mesurée par l’indice Herfindhal-Hirschmann (l’IHH) à partir des catégories socioprofesionnelles que sont les nombre d’ouvriers et d’employés, de professions intermédiaires, de cadres et d’une catégorie regroupant les agriculteurs-exploitants, chefs d’entreprises et artisans. L’équation sous-jacente est la suivante : ∆concentration1980→2019 = 0.10 – 0.33 × concentration1980 ; R2 = 0.16.
Lecture : Quand la concentration socioprofessionnelle d’une commune en 1990 augmente de 10pp, la variation de la concentration socioprofessionnelle entre 1990 et 2019 est en moyenne de -3,3pp.
Interprétation : Les communes tendent à être de moins en moins dissemblables en matière d’hétérogénéité socioprofessionnelle. Autrement dit, les communes les plus homogènes socioprofessionnellement parlant ont vu leur niveau de diversité socioprofessionnelle augmenter plus vite en moyenne depuis 1990.
Figure 8 : Niveau de privilège communal moyen selon le territoire
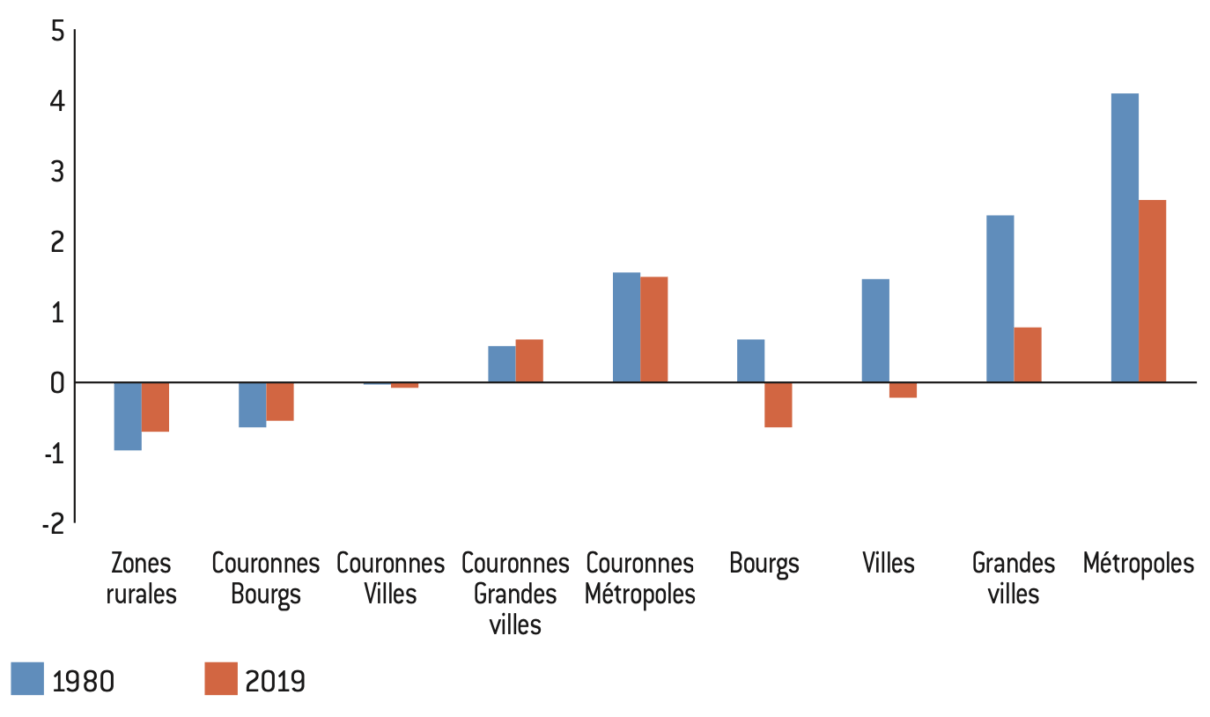
Source :
Calculs de l’auteur à partir des données de l’Insee et de Julia Cagé, Thomas Piketty20.
Note : Le niveau de privilège de chaque commune est obtenu à partir d’une analyse en composante principale incluant les variables suivantes : revenu moyen par adulte, patrimoine immobilier par adulte, part de chaque catégorie socioprofessionnelle, part de chaque catégorie de diplôme, taux de chômage.
Lecture : Le score moyen de privilège dans le couronnes des aires d’attraction de plus 700.000 habitants (métropoles) est de 1,55 en 1980 et 1,52 en 2019.
Interprétation : Les communes des grandes aires d’attraction sont plus privilégiées sur un ensemble de critères regroupant le revenu, le diplôme, les CSP ou le taux de chômage, que ce soit en 1980 ou en 2019. Cependant, cet avantage tend à diminuer dans le temps, ce qui suggère une baisse des écarts de privilège entre les territoires.
Figure 9 : Convergence des niveaux de privilège
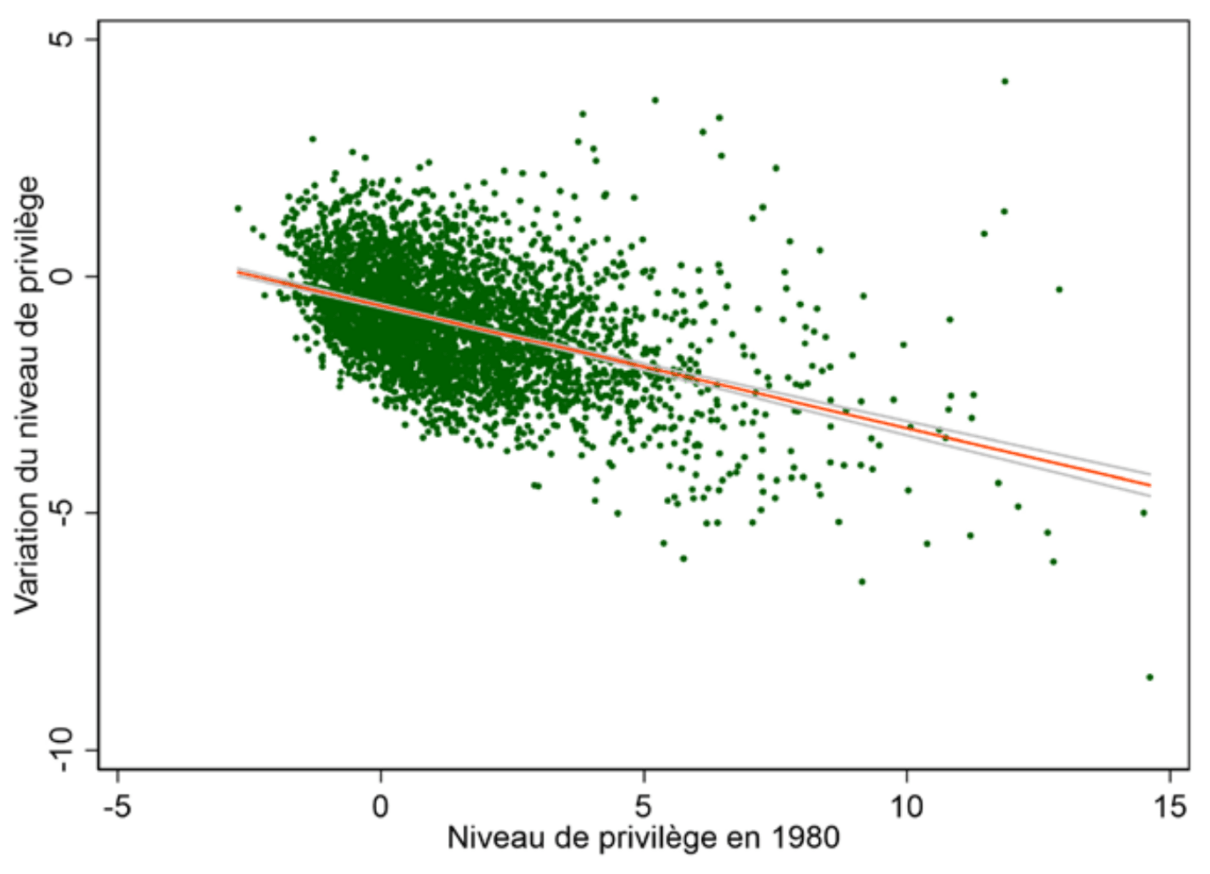
Source :
Calculs de l’auteur à partir des données de l’Insee et de Piketty et Cagé21.
Note : L’équation régissant la relation entre la variation du niveau de privilège et son niveau de 1980 est ∆privilège1980→2019 = 0.61 – 0.26 × privilège1980 ; R2 = 0.19
Lecture : Une augmentation de 10 points du niveau de privilège entraîne une baisse de 2,6 de ce même niveau entre 1980 et 2019.
Interprétation : Plus une commune est privilégiée en 1980, moins son score en la matière augmente en moyenne depuis quarante ans. Il y a donc convergence entre communes sur ce critère composite regroupant le revenu, le diplôme, les CSP ou le taux de chômage.
Figure 10.1 : Part des votes à la présidentielle de 2022 selon l’aire d’attraction à l’élection présidentielle de 2022
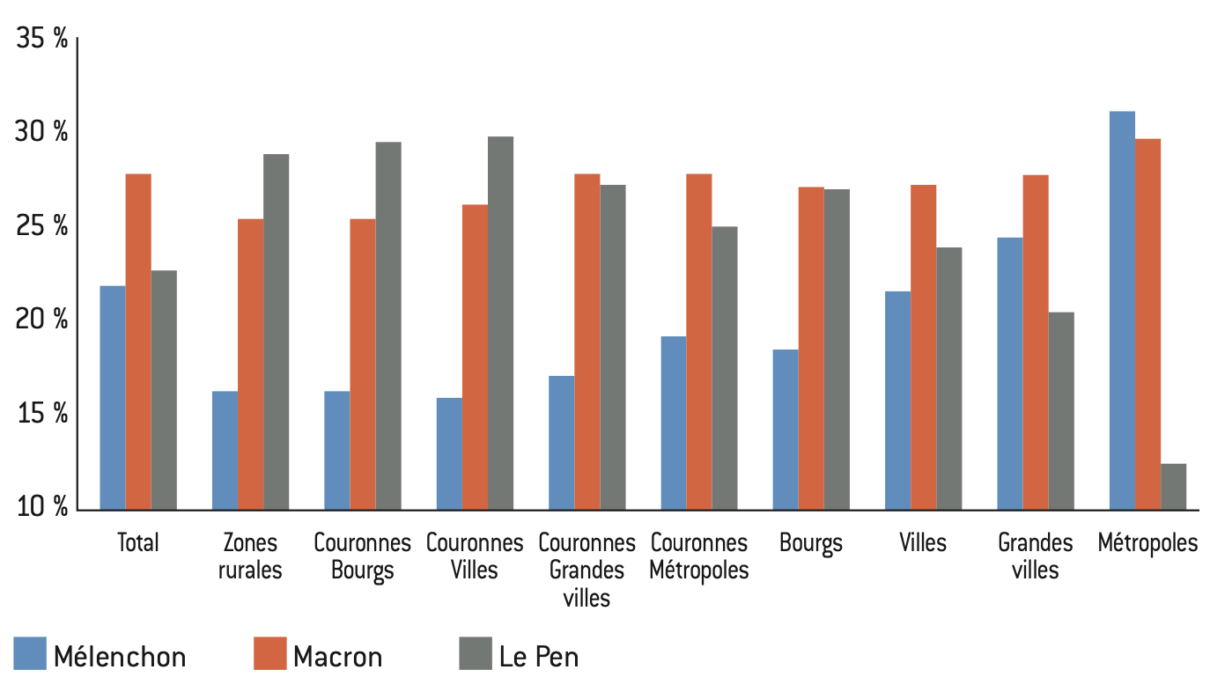
Source :
Calculs de l’auteur à partir des données de l’Insee.
Note : Moyenne de la part des votes obtenus par chaque candidat dans les communes de plus de 1.000 habitants.
Lecture : Dans les couronnes des aires d’attraction de moins de 50.000 habitants (bourgs), Le Pen obtient 29% des voix, contre 26% pour Macron et 16% pour Mélenchon.
Plus la taille de l’agglomération est grande, plus le vote Le Pen/RN diminue, l’inverse s’observe pour Mélenchon/NFP. Le vote Macron/Ensemble est relativement stable quelles que soient les aires d’attraction.
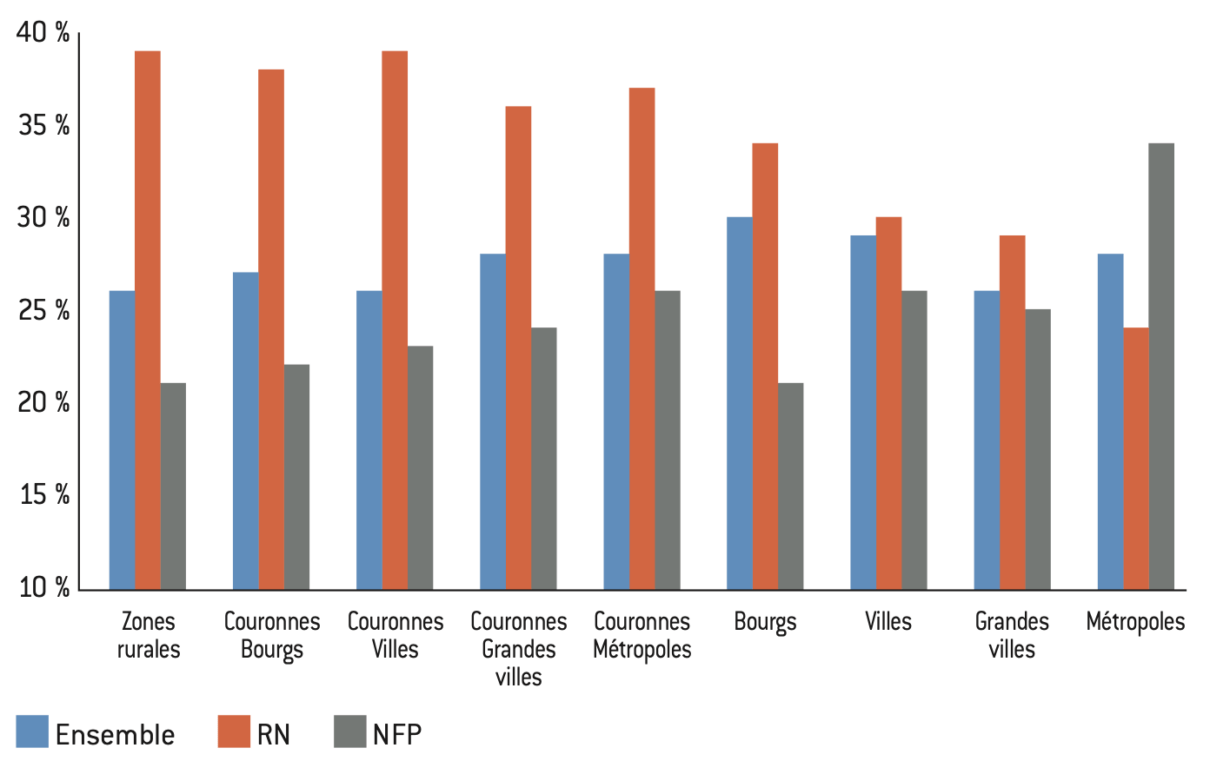
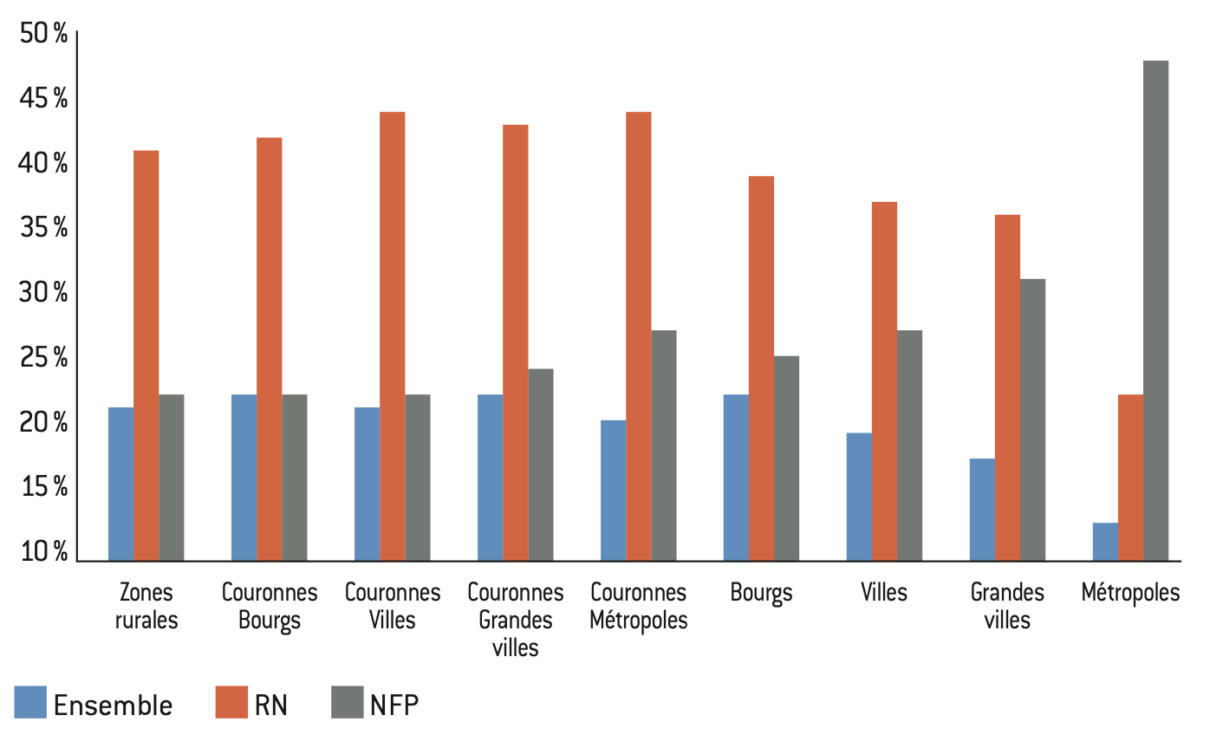
Figure 10.2 Part des votes à la présidentielle de 2022 selon l’aire d’attraction aux élections législatives 2024
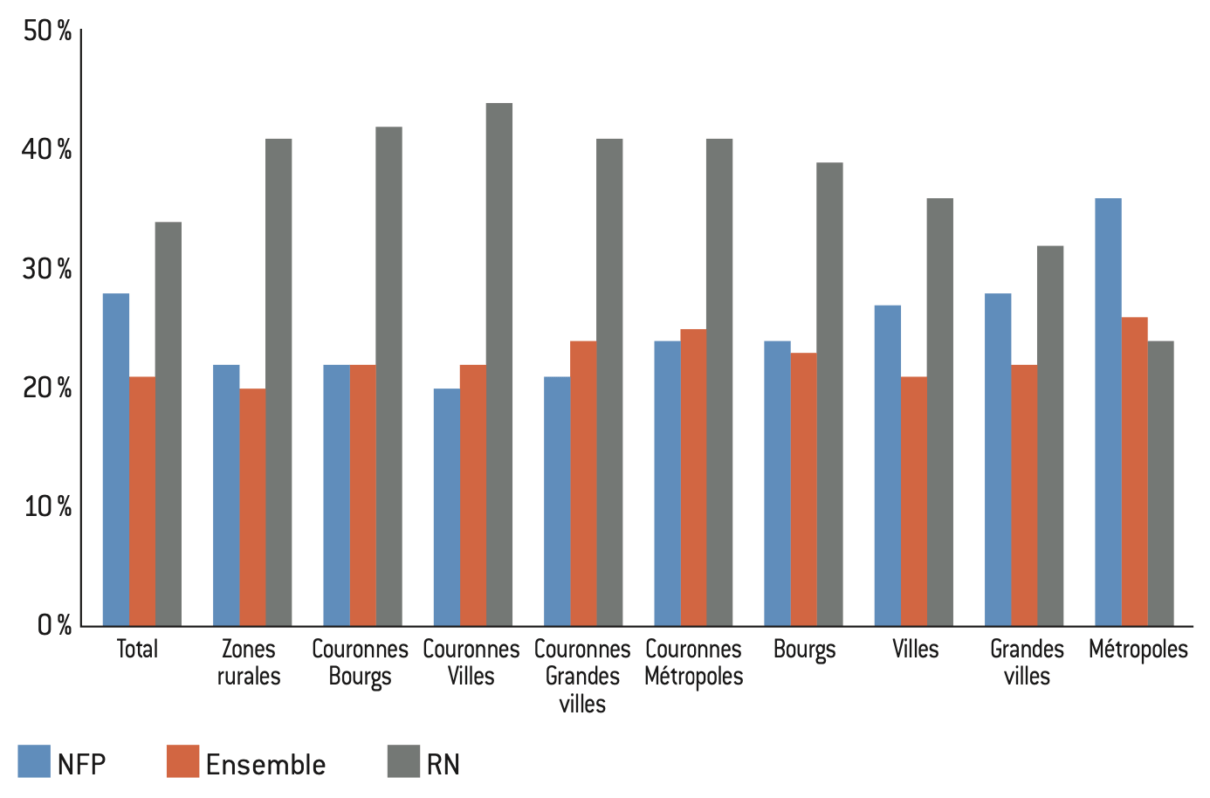
Figure 11.1 : Corrélation entre niveau de privilège et part des votes à l’élection présidentielle de 2022
Source :
Calculs de l’auteur à partir des données de l’Insee et de Piketty et Cagé24.
Note : La corrélation mesure le lien entre niveau de privilège et part des votes obtenus par chaque candidat. Les données excluent les communes de moins de 1.000 habitants. Le niveau de privilège est mesuré tel que décrit dans la section 1.3.
Lecture : Le coefficient de corrélation entre le niveau de privilège et le score obtenu par Yannick Jadot dans les différentes communes de l’échantillon est de 0,63.
Interprétation : Le vote Le Pen /RN est lié aux communes les moins privilégiées. Ce n’est pas le cas du vote Macron/Ensemble. Le vote Mélenchon/NFP semble indépendant du niveau de privilège des communes.
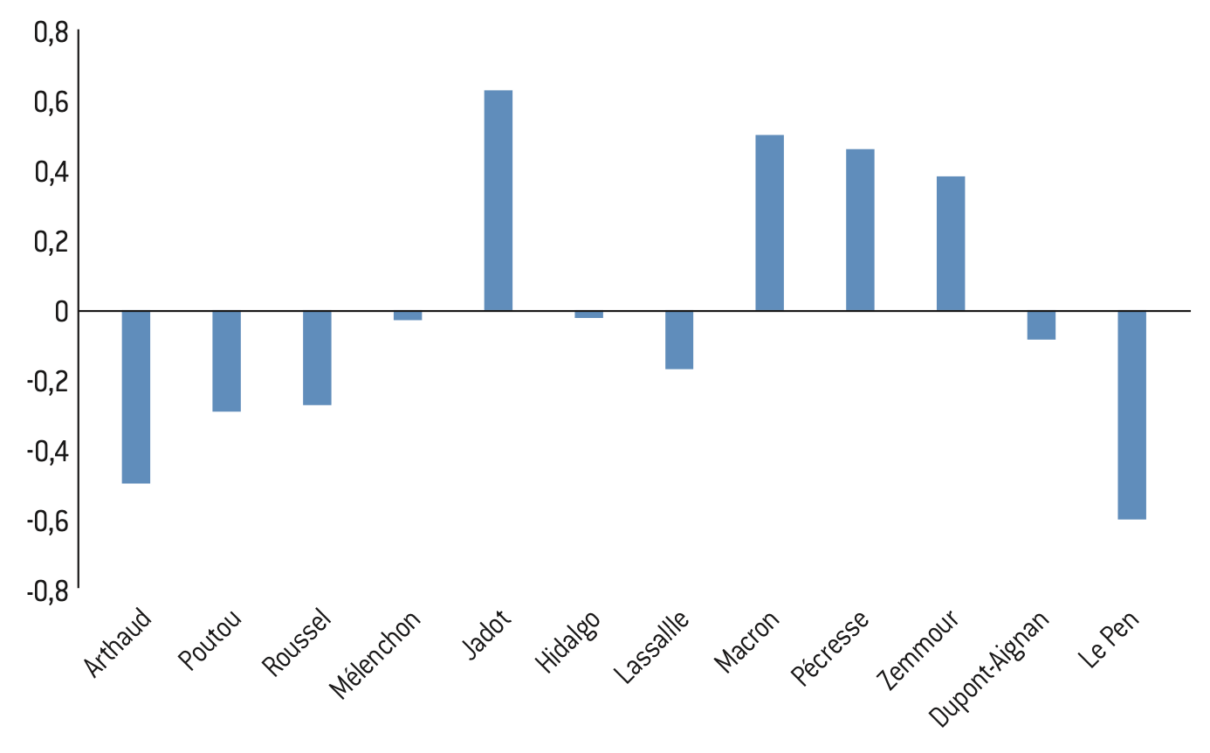
Figure 11.2 : Corrélation entre niveau de privilège et part des votes aux élections législatives de 2024
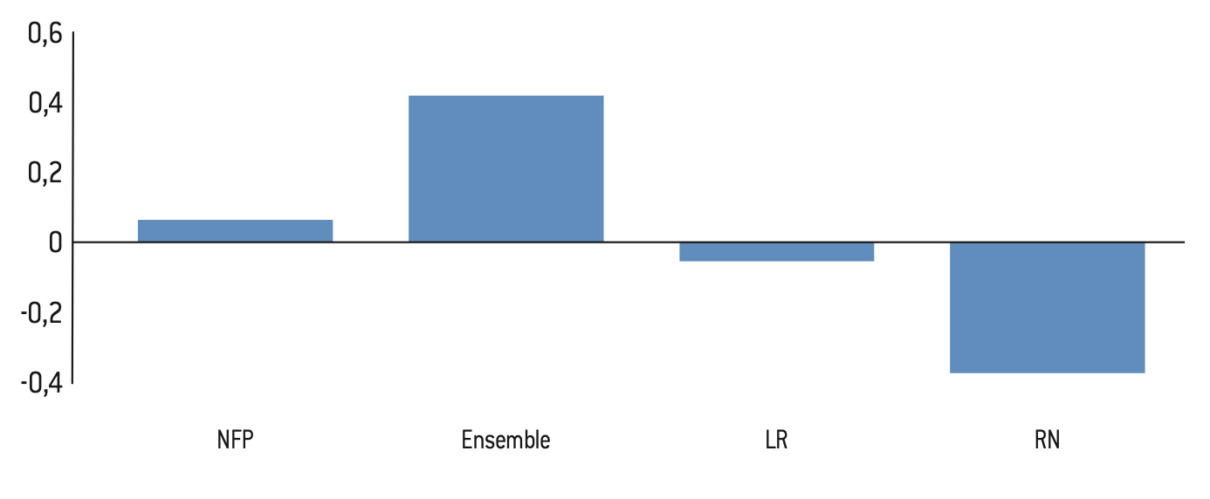
Figure 12.1 : Score relatif des 10% de la population vivant dans les communes privilégiées à l’élection présidentielle de 2022
Source :
Calculs de l’auteur à partir des données de l’Insee et de Piketty et Cagé25.
Note : Le score relatif correspond à la part des votes obtenue parmi les 10% de la population habitant dans les communes les plus privilégiées divisé par le score national du candidat. S’il est supérieur à 1 alors le candidat est davantage plébiscité dans les 10% des communes les plus privilégiées que dans les autres communes.
Lecture : Le score relatif de Valérie Pécresse est de 1,59 ; ainsi, son score est 59% plus élevé parmi la population vivant dans les communes appartenant aux 10% du haut de la distribution du niveau de privilège communal.
Interprétation : Le Pen (2022) et le RN (2024) reçoivent moins de voix depuis les communes parmi les 10% les plus privilégiées. À l’inverse, Macron (2022) et Ensemble (2024) dépendent davantage de cet électorat. Notons que les scores de Mélenchon (2022) et du NFP (2024) sont proches de 1, autrement dit, leur score est le même dans ces communes que dans le reste de la France.
Figure 12.2 : Score relatif des 10% de la population vivant dans les communes privilégiées aux élections législatives de 2024
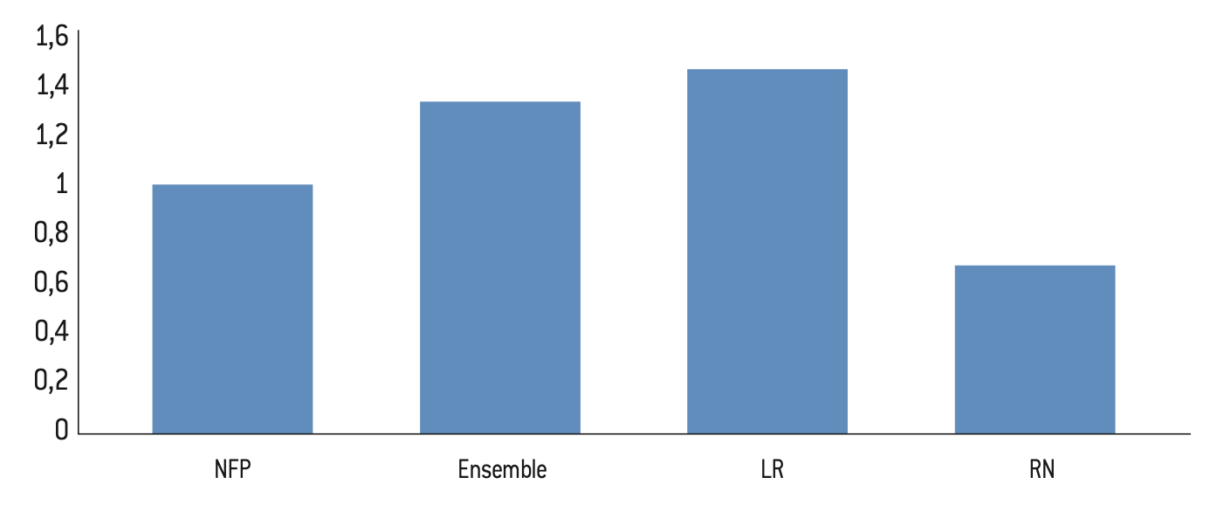
Figure 13.1 : Répartition des voix selon le quintile de privilège communal à l’élection présidentielle de 2022
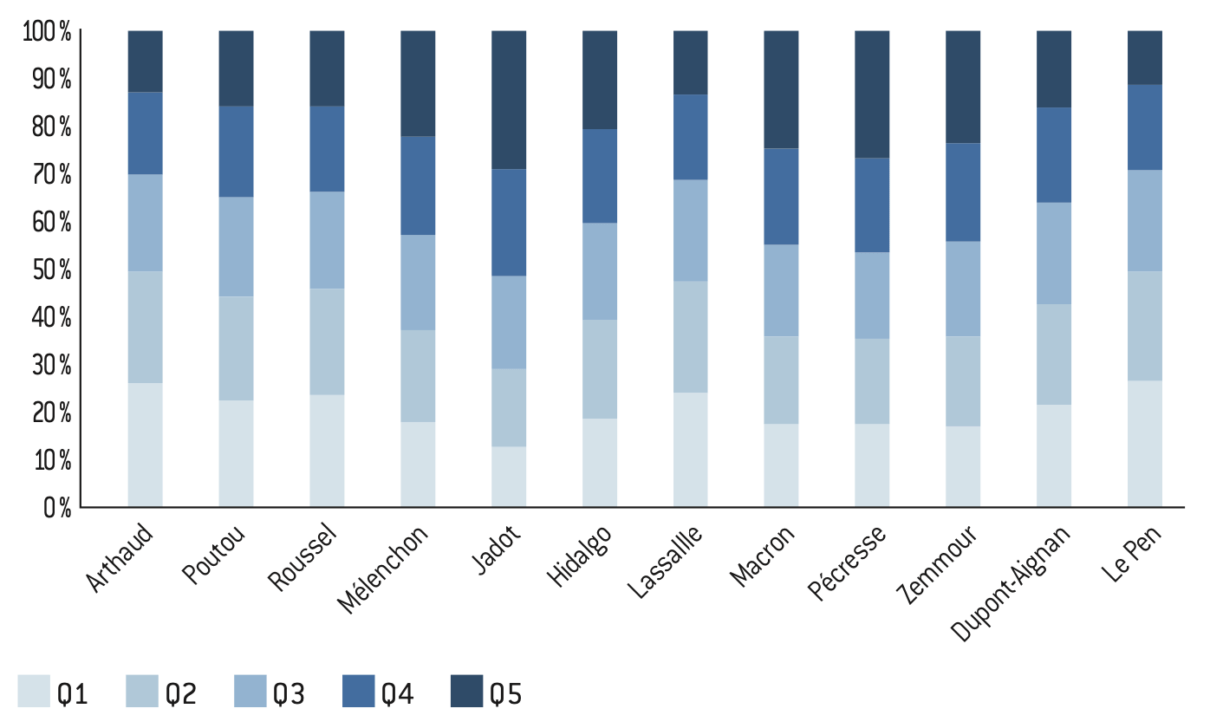
Source :
Calculs de l’auteur à partir des données de l’Insee et de Piketty et Cagé26.
Note : Part des voix de chaque candidat selon le niveau de privilège des communes.
Lecture : 28% des votes obtenus par Nathalie Arthaud proviennent des 20% de la population vivant dans les communes les moins privilégiées ; 49% des votes obtenus par Le Pen proviennent des 40% de la population vivant dans les communes les moins privilégiées.
Interprétation : La plus grande partie de l’électorat de Le Pen/RN se situe dans les communes peu privilégiées. C’est l’inverse pour Macron/Ensemble. Mélenchon/NFP réalise des scores plutôt homogènes selon les quintiles, même s’ils obtiennent moins de voix parmi les 40% du bas de la distribution. Notons que le candidat qui concentre le plus de voix en provenance des communes privilégiées est Y. Jadot.
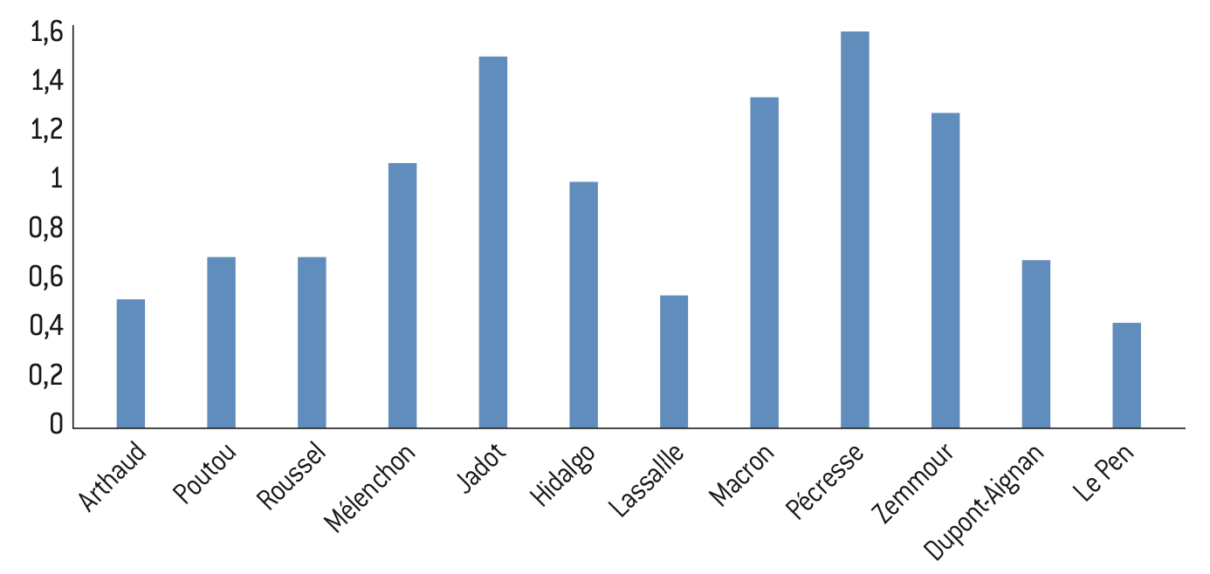
Figure 13.2 : Répartition des voix selon le quintile de privilège communal aux élections législatives de 2024
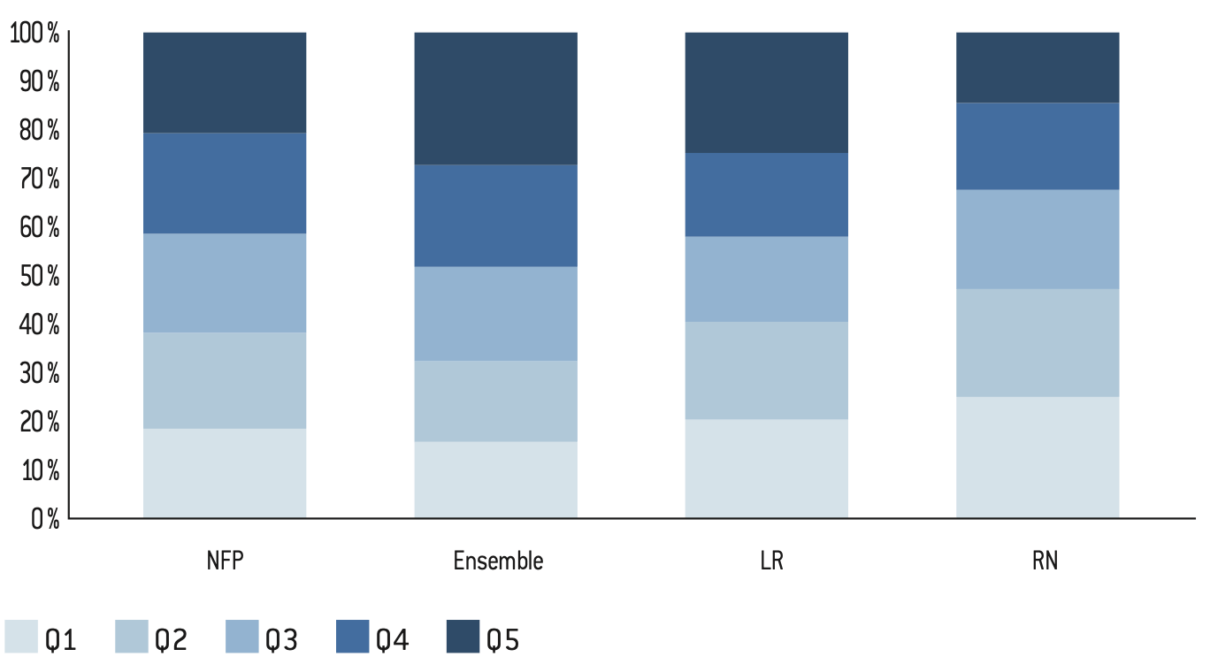
Figure 14.1 : Nombre de voix cumulées par quintile de privilège communal à l’élection présidentielle de 2022
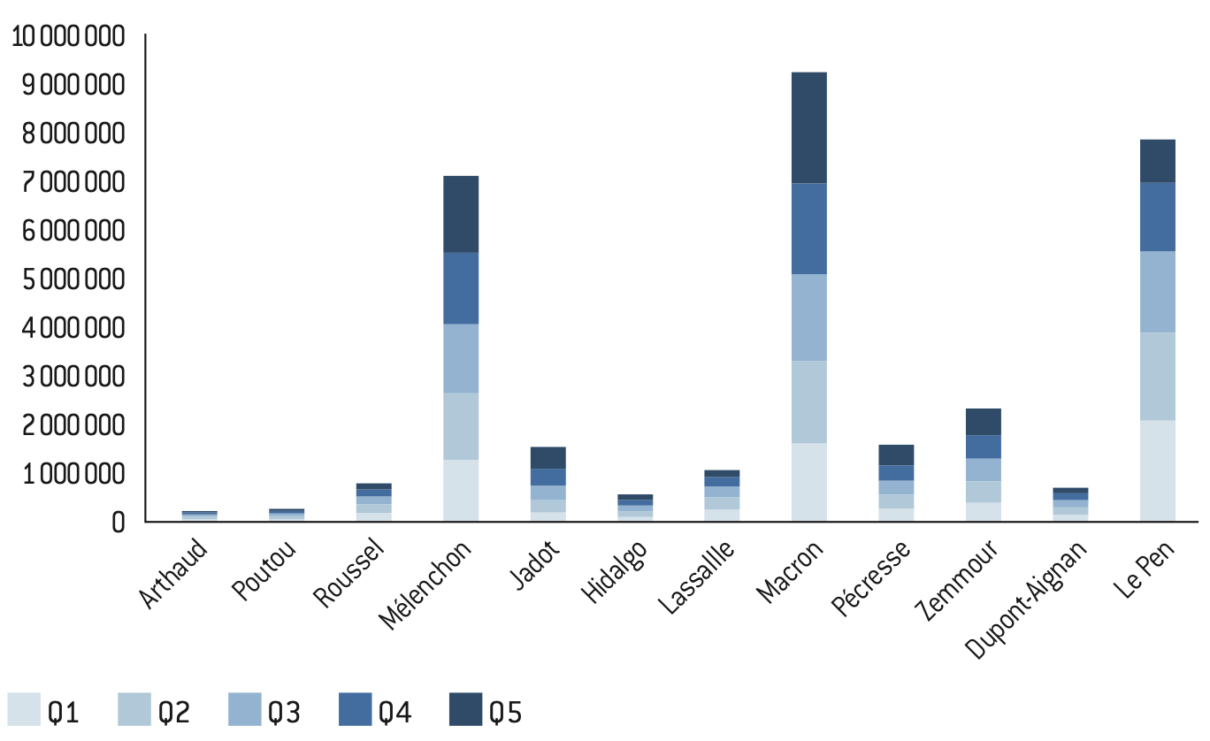
Source :
Calculs de l’auteur à partir des données de l’Insee et de Piketty et Cagé27.
Note : Le vote pour chaque candidat correspond à la somme des votes des communes classées par quintile de privilège. Le niveau de privilège est mesuré à partir de l’agrégation d’un ensemble de variables (revenu, diplôme, CSP, etc.) suivant une analyse en composante principale (cf. section I.3).
Lecture : Mélenchon obtient 1.269.808 voix parmi les 20% de la population vivant dans les communes les moins privilégiées, il obtient 1.559.781 voix parmi les 20% de la population vivant dans les communes les plus privilégiées.
Figure 14.2 : Nombre de voix cumulées par quintile de privilège communal aux élections législatives de 2024
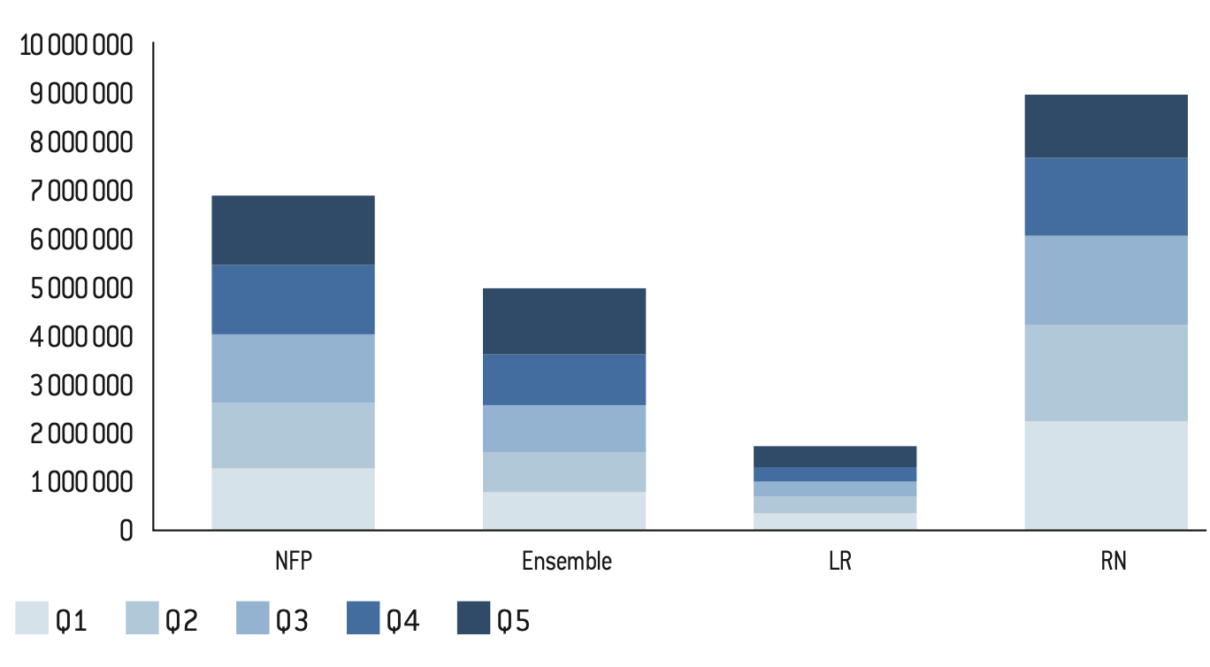
Figure 15.1 : Score communal moyen pour la moitié de la population vivant dans les communes les plus « privilégiées » à l’élection présidentielle de 2022
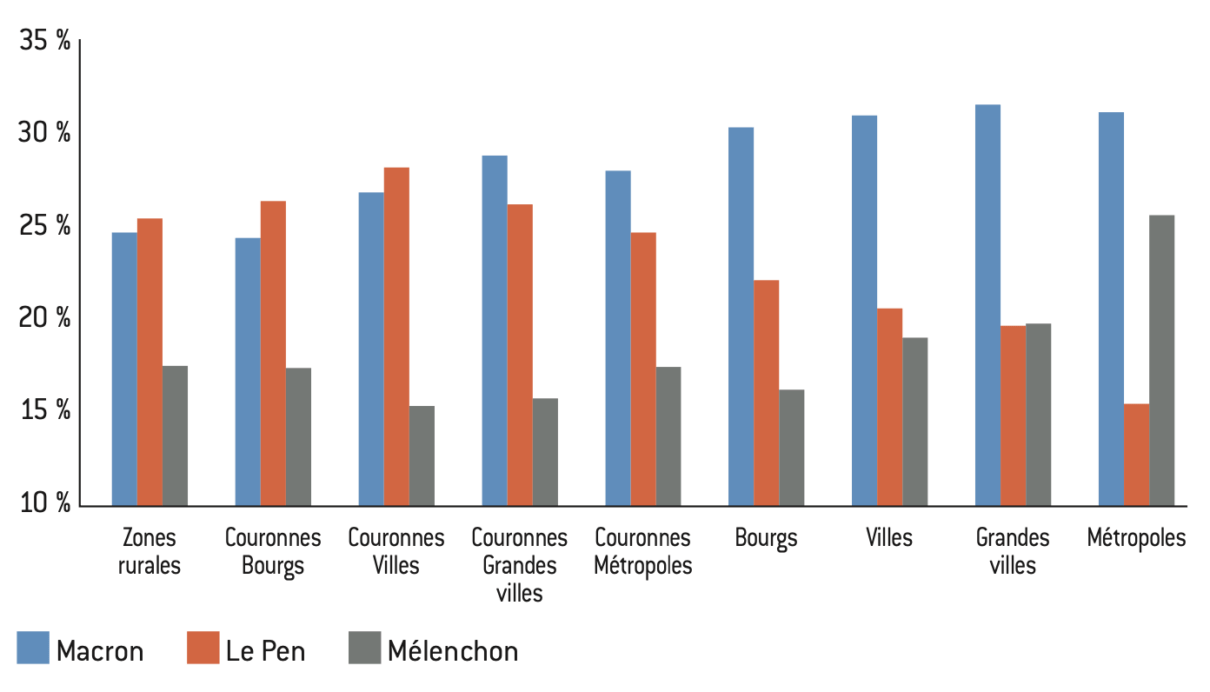
Figure 15.2 : Score communal moyen pour la moitié de la population vivant dans les communes les plus « privilégiées » aux élections législatives de 2024
Source :
Calculs de l’auteur à partir des données de l’Insee et de Piketty et Cagé28.
Note : Le niveau de privilège est mesuré à partir de l’agrégation d’un ensemble de variables (revenu, diplôme, CSP, etc.) suivant une analyse en composante principale (cf. section I.3).
Lecture : Parmi les communes de plus de 1.000 habitants, Macron obtient 32% des voix des communes appartenant au pôle des grandes villes dont la population fait partie des 50% du haut de la distribution du niveau de privilège communal.
Interprétation : Macron apparaît comme le candidat des populations urbaines privilégiées. Cependant, Ensemble chute durant les législatives. Le Pen et le RN sont davantage plébiscités dans les communes rurales, toutefois, le RN est partout en tête à l’exception des pôles des grandes métropoles. Mélenchon et le NFP sont rejetés dans ces communes hormis dans les pôles des grandes métropoles, ce qui coïncide avec l’attrait dont a pu jouir la gauche radicale ou classique parmi les cadres et professions intellectuelles.
Figure 16.1 : Score moyen pour la moitié de la population vivant dans les communes les moins privilégiées à l’élection présidentielle de 2022
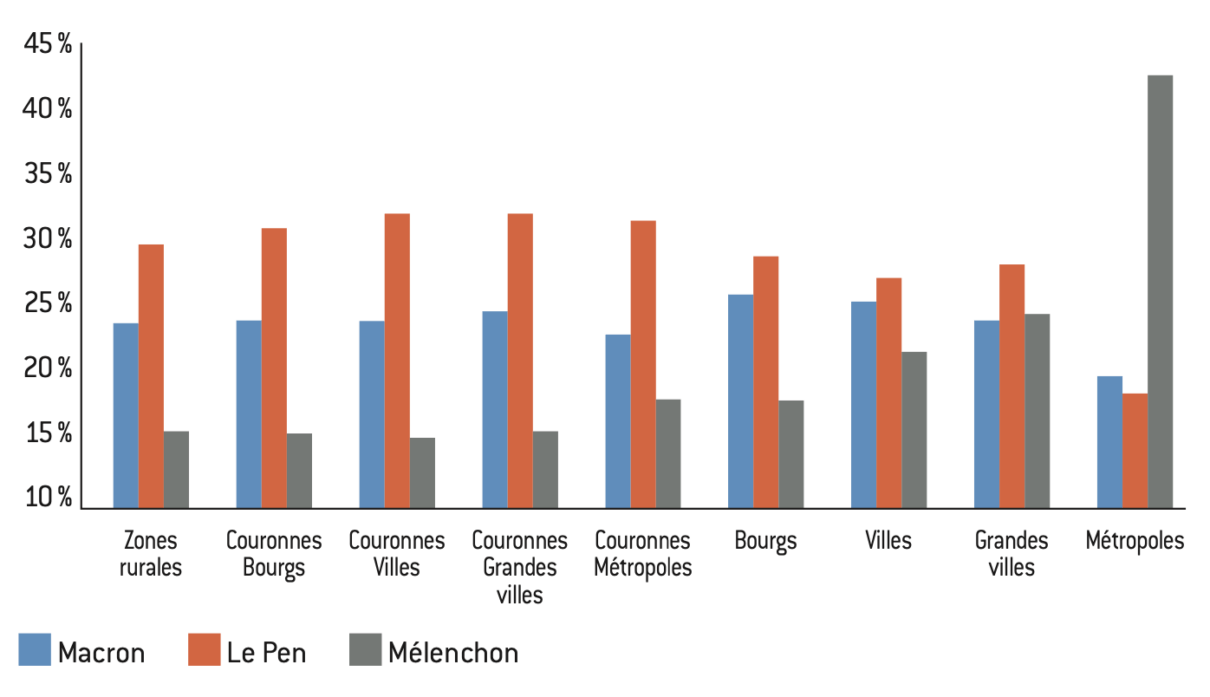
Figure 16.2 : Score moyen pour la moitié de la population vivant dans les communes les moins privilégiées aux élections législatives de 2024
Source :
Calculs de l’auteur à partir des données de l’Insee et de Piketty et Cagé29.
Note : Le niveau de privilège est mesuré à partir de l’agrégation d’un ensemble de variables (revenu, diplôme, CSP, etc.) suivant une analyse en composante principale (cf. section I.3).
Lecture : Parmi les communes de plus de 1.000 habitants, Macron obtient 24% des voix des communes appartenant au pôle des grandes villes dont la population fait partie des 50% du bas de la distribution du niveau de privilège communal.
Interprétation : les populations des communes les moins privilégiées ont surtout voté Le Pen et le RN hormis dans les pôles des grandes métropoles du fait du vote des banlieues. À l’inverse Mélenchon et le NFP font un score relativement faible dans tous les types de communes, hormis dans les grandes métropoles du fait du vote des banlieues. Enfin Macron et Ensemble sous performent dans les communes les moins privilégiées quel que soit le statut géographique.
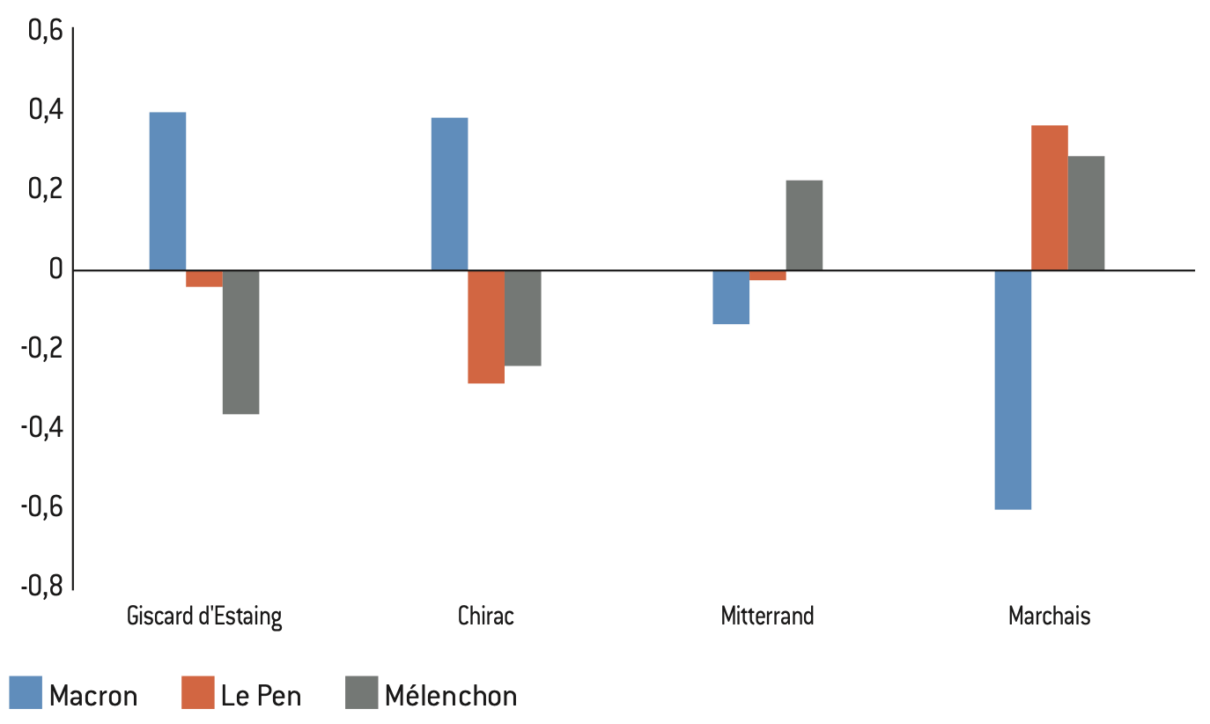
Figure 17 : Corrélation entre candidats aux élections de 1981 et de 2022
Source :
Calculs de l’auteur à partir des données de l’Insee et de Piketty et Cagé30.
Note : La corrélation simple mesure le lien entre le vote des quatre candidats principaux de l’élection de 1981 et les trois candidats principaux de l’élection de 2022.
Lecture : Le coefficient de corrélation entre le score obtenu par Le Pen et Georges Marchais dans les communes de plus de 1.000 habitants est de 0,37. Il est de – 0,61 entre Macron et Marchais et de 0,29 entre Mélenchon et Marchais.
Interprétation : Les votes Macron et Mélenchon reprennent le clivage droite-gauche de 1981, même si les corrélations sont assez faibles (en particulier pour Mélenchon). Le vote Le Pen apparaît quant à lui hors de ce clivage, notamment de par son lien avec le vote Marchais.
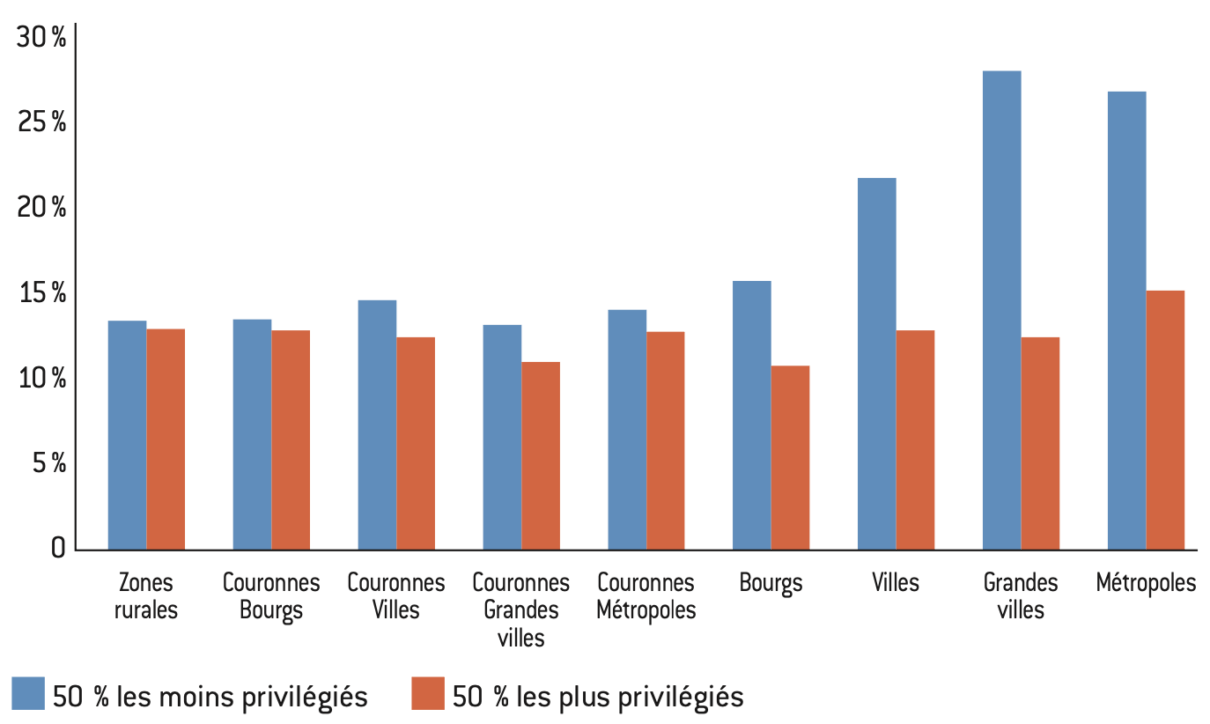
Figure 18 : Score moyen de Georges Marchais en 1981 selon le type de communes
Source :
Calculs de l’auteur à partir des données de l’Insee et de Piketty et Cagé31.
Note : Le niveau de privilège est mesuré à partir de l’agrégation d’un ensemble de variables (revenu, diplôme, CSP, etc.) suivant une analyse en composante principale (cf. section I.3).
Lecture : Le vote Marchais représente 28% des votes au 1er tour de la présidentielle de 1981 dans les communes appartenant aux pôles des grandes villes les moins privilégiées.
Interprétation : Le vote Marchais est un vote populaire qui se concentre en particulier dans les zones urbaines ouvrières.
Figure 19 : Corrélation avec le vote Georges Marchais selon les communes
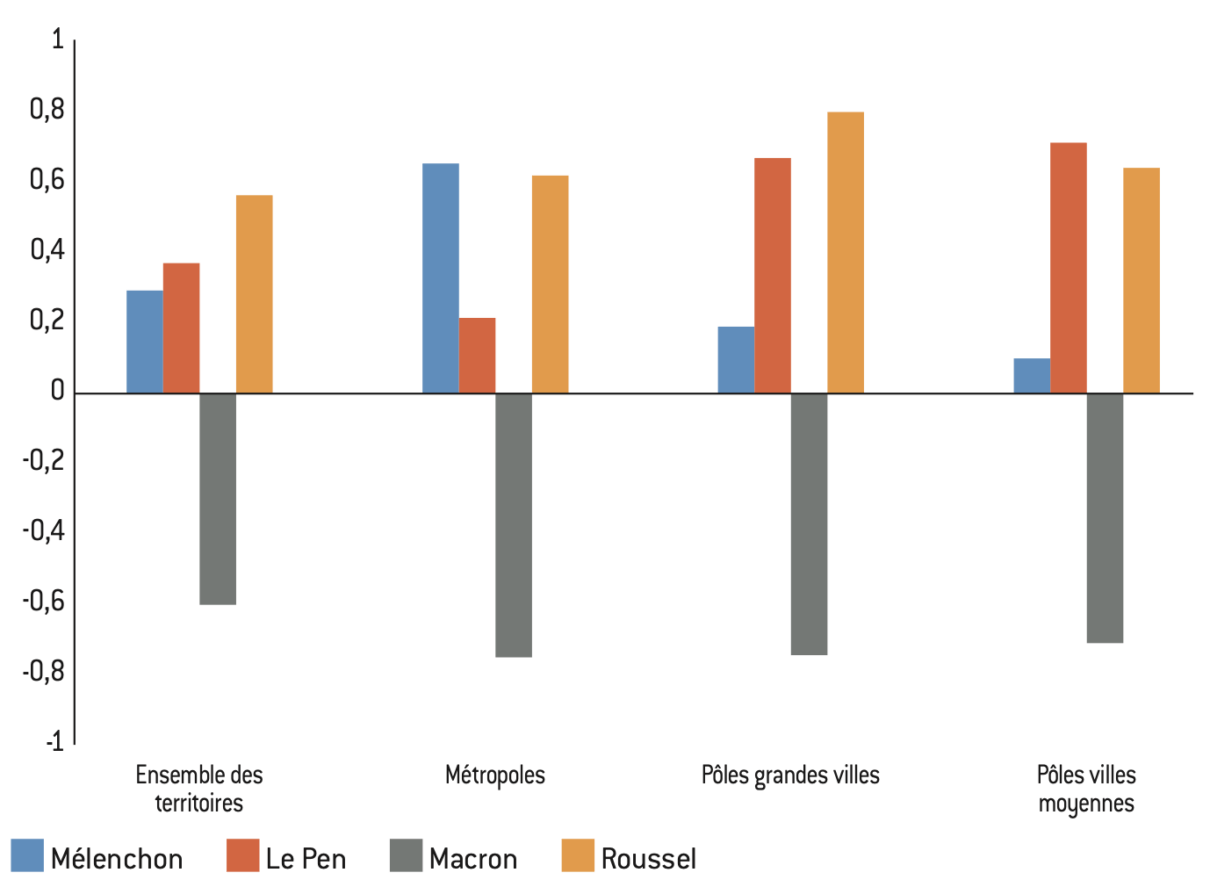
Source :
Calculs de l’auteur à partir des données de l’Insee et de Piketty et Cagé32.
Note : La corrélation simple donne le lien entre le vote Marchais en 1981 et le vote pour l’un des quatre candidats retenus en 2022.
Lecture : Dans les grandes villes, le vote en faveur de Le Pen en 2022 dans les communes de plus de 1.000 habitants est positivement corrélé au vote en faveur de Marchais en 1981. Toutefois cette corrélation est plus faible que la corrélation entre le vote Marchais et Roussel.
Interprétation : Le vote en faveur de Marchais est positivement corrélé au vote Le Pen et Roussel et négativement corrélé au vote Macron. En revanche, le vote Mélenchon apparaît faiblement lié au vote Marchais en dehors des banlieues des grandes métropoles. Une modification de la composition des votes en faveur de la gauche radicale s’est opérée, le vote Mélenchon apparaissant faiblement lié au vote populaire historique, notamment celui des ouvriers, qui lui préfèrent Le Pen.
Figure 20 : Corrélation Le Pen/Mitterrand ou Macron/Giscard d’Estaing, second tour 2022/1981
Source :
Calculs de l’auteur à partir des données de l’Insee et de Piketty et Cagé33.
Note : La corrélation simple donne le lien entre le vote Mitterrand ou Giscard d’Estaing d’une part et le vote Le Pen ou Macron d’autre part.
Lecture : Dans les zones rurales, le vote en faveur de Le Pen en 2022 dans les communes de plus de 1.000 habitants est positivement corrélé au vote en faveur de Mitterrand en 2022. Toutefois cette corrélation est plus faible que dans les bourgs.
Interprétation : Le vote Macron est positivement associé au vote Giscard d’Estaing alors que le vote Le Pen est positivement corrélé au vote Mitterrand, et ce, quel que soit le territoire considéré. Le lien apparaît particulièrement fort dans les pôles des villes hors grandes métropoles, c’est-à-dire là où les ouvriers se concentrent historiquement.
Figure 21.1 : Corrélation entre part des votes et variables économiques et sociales à l’élection présidentielle de 2022
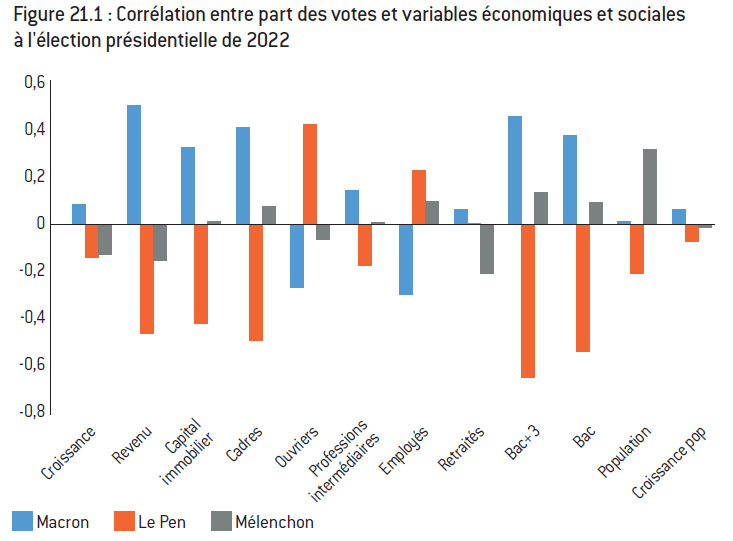
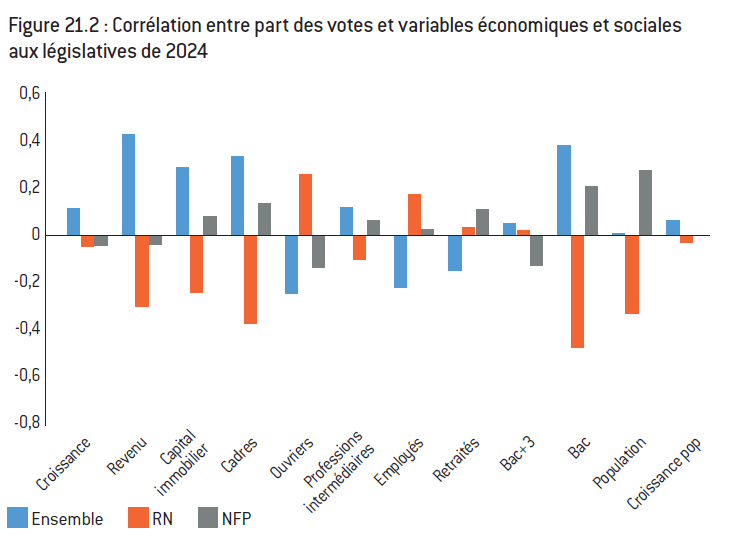
Figure 21.2 : Corrélation entre part des votes et variables économiques et sociales aux législatives de 2024
Source :
Calculs de l’auteur à partir des données de l’Insee et de Piketty et Cagé34.
Note : La corrélation simple mesure le lien entre chaque variable et le vote pour chacun des candidats.
Lecture : Le vote en faveur de Le Pen dans les communes de plus de 1.000 habitants est positivement corrélé à la part des ouvriers dans la population active de la commune.
Interprétation : Le vote pour Le Pen et le RN ainsi que le vote en faveur de Macron d’Ensemble s’opposent sur les différentes dimensions retenues ici (revenu, CSP, diplôme). À l’inverse le vote Mélenchon et NFP est faiblement corrélé à chacune des variables, ce qui suggère une plus forte hétérogénéité du vote de gauche, même si la population des communes semble influente du fait de l’importance du vote des pôles.
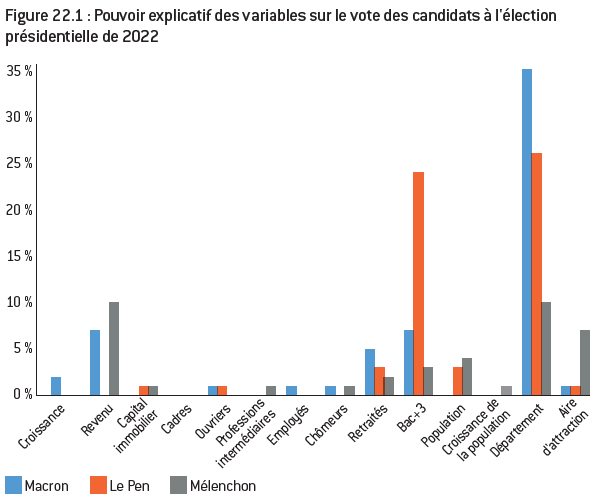
Figure 22.1 : Pouvoir explicatif des variables sur le vote des candidats à l’élection présidentielle de 2022
Source :
Source : Calculs de l’auteur à partir des données de l’Insee et de Piketty et Cagé35.
Note : Le pouvoir explicatif d’une variable sur le vote d’un candidat est mesuré par le corrélation partielle après prise en compte de toutes les variables pertinentes.
Lecture : La part de la population ayant au moins un diplôme au niveau bac+3 dans les communes de plus de 1.000 explique 19% de la variance du score de Le Pen une fois pris en compte l’effet des autres variables sur ce même score.
Interprétation : Les seules variables ayant un pouvoir explicatif sur le vote des trois candidats/ partis principaux sont le département d’appartenance, le revenu moyen, la part des retraités et le niveau de diplôme. Le niveau de diplôme apparaît comme la variable expliquant le mieux le vote populiste de droite masquant ainsi tout effet du revenu ou du statut socioprofessionnel.
Figure 22.2 : Pouvoir explicatif des variables sur le vote des candidats aux élections législatives de 2024
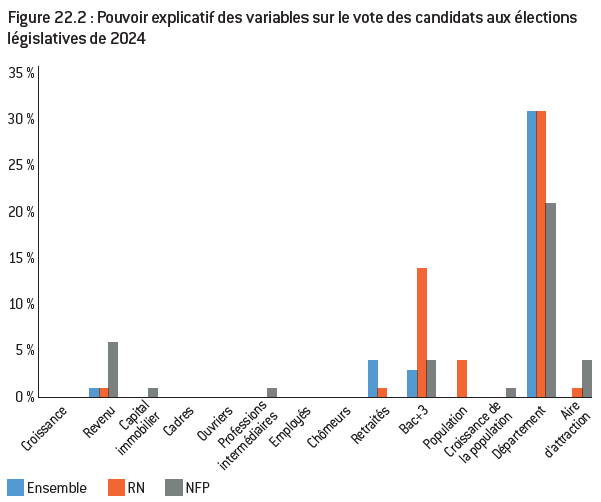
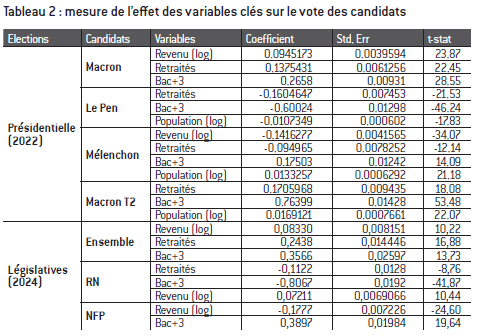
Tableau 2 : mesure de l’effet des variables clés sur le vote des candidats
Source :
Calculs de l’auteur à partir des données de l’Insee et de Piketty et Cagé44.
Note : Les coefficients estimés ici le sont à partir d’un modèle de sélection bayésien (Bayesian Model Averaging). Seules les variables les plus pertinentes ont été retenues ici.
Lecture : Lorsque le revenu augmente de 1%, le vote en faveur de Mélenchon diminue de 0,14pp.
Interprétation : le revenu est la variable qui a le plus grand effet sur le vote Mélenchon/NFP. Le niveau de diplôme est la variable qui a le plus grand effet sur le vote Le Pen/RN. Même si le vote Le Pen/RN est davantage le fait des populations les moins aisées, le revenu ne semble pas être l’élément le plus déterminant. En effet, les moins aisés ont surtout voté Le Pen/RN parce qu’ils sont aussi moins diplômés.











Aucun commentaire.